
概述
Failover是 Redis Cluster 提供的容错机制,cluster最核心的功能之一。
Failover 支持两种模式:
- 故障 Failover:自动恢复集群的可用性
- 人为 Failover:支持集群的可运维操作
本文主要分析故障自动 Failover 的过程,即当 Master 不能提供服务时,Slave 自动 Failover 替换主节点的过程。
我将从两部分展开源码进行剖析,第一部分介绍实现 Redis Cluster Failover 的前提,即通过 Gossip 协议进行故障检测,第二部分介绍 Slave 识别到故障后进行拉票完成 Failover 的过程。
故障检测
每个 Redis 节点会周期性通过 Gossip 协议传递节点状态和数据
周期发送消息源码(Redis 5.0):
// server.c
/* Run the Redis Cluster cron. */
// 100 ms执行一次(1秒10次)
run_with_period(100) {
if (server.cluster_enabled) clusterCron();
}
// cluster.c
void clusterCron(void) {
/.../
// 遍历集群所有节点(集群节点是维护在 redis dict 中)
di = dictGetSafeIterator(server.cluster->nodes);
server.cluster->stats_pfail_nodes = 0;
// 第一次遍历,主要是检查我们是否有断开连接的节点,并进行连接的重新建立。
while((de = dictNext(di)) != NULL) {
clusterNode *node = dictGetVal(de);
/.../
// 若没有连接,重连节点
if (node->link == NULL) {
int fd;
mstime_t old_ping_sent;
clusterLink *link;
fd = anetTcpNonBlockBindConnect(server.neterr, node->ip,
node->cport, NET_FIRST_BIND_ADDR);
if (fd == -1) {
/* We got a synchronous error from connect before
* clusterSendPing() had a chance to be called.
* If node->ping_sent is zero, failure detection can't work,
* so we claim we actually sent a ping now (that will
* be really sent as soon as the link is obtained). */
if (node->ping_sent == 0) node->ping_sent = mstime();
serverLog(LL_DEBUG, "Unable to connect to "
"Cluster Node [%s]:%d -> %s", node->ip,
node->cport, server.neterr);
continue;
}
link = createClusterLink(node);
/.../
// 发送 MEET 或 PING MSG
clusterSendPing(link, node->flags & CLUSTER_NODE_MEET ?
CLUSTERMSG_TYPE_MEET : CLUSTERMSG_TYPE_PING);
/.../
}
}
dictReleaseIterator(di);
/* Ping some random node 1 time every 10 iterations, so that we usually ping
* one random node every second. */
// iteration 由 static 修饰,说明是全局变量,在每次调用 clusterCron 时会自增
// 进入条件是 iteration 能被 10 整除(iteration % 10 == 0, if(非0) 时为真 ),
// 实现每 10 次调用进入该方法 1 次,即每秒1次。
// 目的是随机获取几个节点,并选择其中 PONG 接受时间最老的节点发送 PING 请求。
if (!(iteration % 10)) {
int j;
/* Check a few random nodes and ping the one with the oldest
* pong_received time. */
for (j = 0; j < 5; j++) {
// 获取随机节点
de = dictGetRandomKey(server.cluster->nodes);
clusterNode *this = dictGetVal(de);
/* Don't ping nodes disconnected or with a ping currently active. */
if (this->link == NULL || this->ping_sent != 0) continue;
if (this->flags & (CLUSTER_NODE_MYSELF|CLUSTER_NODE_HANDSHAKE))
continue;
if (min_pong_node == NULL || min_pong > this->pong_received) {
min_pong_node = this;
min_pong = this->pong_received;
}
}
// 发送 PING
if (min_pong_node) {
serverLog(LL_DEBUG,"Pinging node %.40s", min_pong_node->name);
clusterSendPing(min_pong_node->link, CLUSTERMSG_TYPE_PING);
}
}
/* Iterate nodes to check if we need to flag something as failing.
* This loop is also responsible to:
* 1) Check if there are orphaned masters (masters without non failing
* slaves).
* 2) Count the max number of non failing slaves for a single master.
* 3) Count the number of slaves for our master, if we are a slave. */
orphaned_masters = 0;
max_slaves = 0;
this_slaves = 0;
// 第二次遍历,主要负责孤立 master 检查、slave 数量统计、标记节点 PFAIL 状态等等。
di = dictGetSafeIterator(server.cluster->nodes);
while((de = dictNext(di)) != NULL) {
clusterNode *node = dictGetVal(de);
now = mstime(); /* Use an updated time at every iteration. */
mstime_t delay;
if (node->flags &
(CLUSTER_NODE_MYSELF|CLUSTER_NODE_NOADDR|CLUSTER_NODE_HANDSHAKE))
continue;
/.../
/* If we have currently no active ping in this instance, and the
* received PONG is older than half the cluster timeout, send
* a new ping now, to ensure all the nodes are pinged without
* a too big delay. */
// 如果遍历到的节点和当前节点之前没有正在发送的 PING, 并且最近收到 PONG 比集群超时时间的一半还要长,
// 那么就发送一个 PING, 以保证所有的节点都和当前的节点之间的 PING 通,并且延迟不会太高
if (node->link &&
node->ping_sent == 0 &&
(now - node->pong_received) > server.cluster_node_timeout/2)
{
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
/* If we are a master and one of the slaves requested a manual
* failover, ping it continuously. */
// mf = manual failover 手动故障转移,这里表示手动 failover 正在进行
// mf_slave 指向正在进行 mf 的 slave
// 这里表示当前节点是 master,并且遍历到的 slave正在 mf,那么向该 slave 发送 PING
if (server.cluster->mf_end &&
nodeIsMaster(myself) &&
server.cluster->mf_slave == node &&
node->link)
{
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
/.../
/* Check only if we have an active ping for this instance. */
if (node->ping_sent == 0) continue;
/* Compute the delay of the PONG. Note that if we already received
* the PONG, then node->ping_sent is zero, so can't reach this
* code at all. */
delay = now - node->ping_sent;
// 超时未收到 PONG 标记 PFAIL
if (delay > server.cluster_node_timeout) {
/* Timeout reached. Set the node as possibly failing if it is
* not already in this state. */
if (!(node->flags & (CLUSTER_NODE_PFAIL|CLUSTER_NODE_FAIL))) {
serverLog(LL_DEBUG,"*** NODE %.40s possibly failing",
node->name);
node->flags |= CLUSTER_NODE_PFAIL;
update_state = 1;
}
}
}
dictReleaseIterator(di);
/.../
}
可以看到 clusterCron 发送 PING 消息包括四种逻辑:
- 每 100ms 遍历所有断开连接的节点,发送 PING;
- 每 100ms 随机选择 1 个 PONG 接受时间最老的节点,发送 PING;
- 每 100ms 针对所有 PONG 接受时间 > cluster_node_timeout / 2 的节点发送 PING(cluster_node_timeout 默认 15000ms 即 15 秒);
- 若当前节点是 master,那么每 100ms 针对所有正在进行 manual failover 且属于当前节点的从节点的节点,发送 PING。
void clusterSendPing(clusterLink *link, int type) {
unsigned char *buf;
clusterMsg *hdr;
int gossipcount = 0; /* Number of gossip sections added so far. */
int wanted; /* Number of gossip sections we want to append if possible. */
int totlen; /* Total packet length. */
// freshnodes 表示发送的 PING 消息中最大节点数,值为集群总节点数 - 2(去掉当前节点和目标节点)
// 然而实际上节点要更少,比如正在握手的节点、断开连接的节点。
int freshnodes = dictSize(server.cluster->nodes)-2;
// wanted 表示实际想要发送消息体中的节点个数,这里取总节点数的 1/10 且至少为3个。
// 如果 wanted 太大,会增加消息体大小,增加集群的额外通信负担;而太小又会使节点无法获知较多其他节点的状态,影响集群最终一致的时间。
// 那为什么是 1/10 呢?
// 作者 COMMENT 翻译:
// 如果我们有 N 个 master node,那么取 1/10 就是要添加 N/10 个节点信息到消息体数组(clusterMsgDataGossip)中,
// 考虑在节点交互超时时间内,我们和其他节点交互至少 4 个报文(因为节点最长经过 cluster_node_timeout/2 就会向其他节点发送一次 PING 包,
// 那就会收到一个 PONG,即在 cluster_node_timeout 时间内就会发送 2 个 PING,收到 2 个 PONG)。
// 那么,在下线检测时间 cluster_node_timeout*2 内,就是 8 个报文。所以,对于一个 PFAIL node,我们可以预期收到故障报告数量为:
// (cluster_node_timeout*2 时间内)
// PROB * GOSSIP_ENTRIES_PER_PACKET * TOTAL_PACKETS:
// PROB = 一个节点被包含在一个消息中的几率(从所有节点挑一个节点,即 1/总节点数);
// GOSSIP_ENTRIES_PER_PACKET = 一个消息中节点数量,即 N/10;
// TOTAL_PACKETS = 所有节点交换的总包数,即 master 节点数 * 8;
// 假设只有 master node,即节点数量就是主节点数量,那么取1/10就可以获得大多数信息。即达到大概 80% 的节点数量,在同时间段有大部分主节点报告故障节点。
// 因为根据公式:1/num_of_nodes * (n / 10) * num_of_nodes * 8 = 8/10 * n
// 总结就是:消息中的节点数量与 Redis Cluster 的 Failover 机制相关,因为计算 Failover 的超时时间是 cluster-node-timeout * 2,
// 那这段时间内就能收发 8 个 PING + PONG 心跳包,每个心跳包中实例个数设置为集群的 1/10,那在故障转移时间限制内,
// 所有消息里的节点数量就是集群的 80%(即 8 * 1/10)节点的故障状态信息了,足以集群确认某个节点(PFAIL节点)存在问题了。
// 对于这个值不必太纠结,本身是作者估算的值,比如如果收发的消息节点是重复的,那就只包含 40% 的节点消息了。只能说在大部分情况下,这个值是正确的。
// 另外,4.0 后又加了 pfail_wanted,使得对于 PFAIL 节点消息能够更快传播了。
// 节点数除以 10 并向下取整
wanted = floor(dictSize(server.cluster->nodes)/10);
if (wanted < 3) wanted = 3;
if (wanted > freshnodes) wanted = freshnodes;
/* Include all the nodes in PFAIL state, so that failure reports are
* faster to propagate to go from PFAIL to FAIL state. */
// 包括所有处于 PFAIL 状态节点,以便故障报告能够尽快通过 GOSSIP 传播,帮助 PFAIL 尽快变为 FAIL
int pfail_wanted = server.cluster->stats_pfail_nodes;
/* Compute the maxium totlen to allocate our buffer. We'll fix the totlen
* later according to the number of gossip sections we really were able
* to put inside the packet. */
// 计算包长度 totlen
totlen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
totlen += (sizeof(clusterMsgDataGossip)*(wanted+pfail_wanted));
/.../
/* Populate the header. */
// 填充 Header
if (link->node && type == CLUSTERMSG_TYPE_PING)
link->node->ping_sent = mstime();
clusterBuildMessageHdr(hdr,type);
/* Populate the gossip fields */
// 最大迭代次数 = wanted * 3
int maxiterations = wanted*3;
while(freshnodes > 0 && gossipcount < wanted && maxiterations--) {
// 随机取一个节点
dictEntry *de = dictGetRandomKey(server.cluster->nodes);
clusterNode *this = dictGetVal(de);
/* Don't include this node: the whole packet header is about us
* already, so we just gossip about other nodes. */
if (this == myself) continue;
/* PFAIL nodes will be added later. */
if (this->flags & CLUSTER_NODE_PFAIL) continue;
/* In the gossip section don't include:
* 1) Nodes in HANDSHAKE state.
* 3) Nodes with the NOADDR flag set.
* 4) Disconnected nodes if they don't have configured slots.
*/
if (this->flags & (CLUSTER_NODE_HANDSHAKE|CLUSTER_NODE_NOADDR) ||
(this->link == NULL && this->numslots == 0))
{
freshnodes--; /* Tecnically not correct, but saves CPU. */
continue;
}
/* Do not add a node we already have. */
if (clusterNodeIsInGossipSection(hdr,gossipcount,this)) continue;
/* Add it */
// 经过一系列判断符合条件的 node 添加到消息体
clusterSetGossipEntry(hdr,gossipcount,this);
freshnodes--; // 最大阈值-1
gossipcount++; // 已添加节点数+1
}
/* If there are PFAIL nodes, add them at the end. */
// 添加所有 PFAIL 节点
if (pfail_wanted) {
dictIterator *di;
dictEntry *de;
di = dictGetSafeIterator(server.cluster->nodes);
while((de = dictNext(di)) != NULL && pfail_wanted > 0) {
clusterNode *node = dictGetVal(de);
if (node->flags & CLUSTER_NODE_HANDSHAKE) continue;
if (node->flags & CLUSTER_NODE_NOADDR) continue;
if (!(node->flags & CLUSTER_NODE_PFAIL)) continue;
clusterSetGossipEntry(hdr,gossipcount,node);
freshnodes--;
gossipcount++;
/* We take the count of the slots we allocated, since the
* PFAIL stats may not match perfectly with the current number
* of PFAIL nodes. */
pfail_wanted--;
}
dictReleaseIterator(di);
}
/* Ready to send... fix the totlen fiend and queue the message in the
* output buffer. */
totlen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
totlen += (sizeof(clusterMsgDataGossip)*gossipcount);
hdr->count = htons(gossipcount);
hdr->totlen = htonl(totlen);
// 添加消息到发送队列排队准备发送
clusterSendMessage(link,buf,totlen);
zfree(buf);
}
/* Set the i-th entry of the gossip section in the message pointed by 'hdr'
* to the info of the specified node 'n'. */
// 添加节点数据到 header 的 data(消息体)对应 ping.gossip 数组第 i 项。
void clusterSetGossipEntry(clusterMsg *hdr, int i, clusterNode *n) {
clusterMsgDataGossip *gossip;
gossip = &(hdr->data.ping.gossip[i]);
memcpy(gossip->nodename,n->name,CLUSTER_NAMELEN);
gossip->ping_sent = htonl(n->ping_sent/1000);
gossip->pong_received = htonl(n->pong_received/1000);
memcpy(gossip->ip,n->ip,sizeof(n->ip));
gossip->port = htons(n->port);
gossip->cport = htons(n->cport);
gossip->flags = htons(n->flags);
gossip->notused1 = 0;
}
Gossip 消息主要包括消息头(clusterMsg )和消息体(clusterMsgData)两部分,结构体定义如下(Redis 5.0):
// cluster.h
// 集群消息的结构(消息头,header)
typedef struct {
char sig[4]; /* Signature "RCmb" (Redis Cluster message bus). */
// 消息的长度(包括这个消息头的长度和消息正文的长度)
uint32_t totlen; /* Total length of this message */
uint16_t ver; /* Protocol version, currently set to 1. */
uint16_t port; /* TCP base port number. */
// 消息的类型
uint16_t type; /* Message type */
// 消息正文包含的节点信息数量
// 只在发送 MEET 、 PING 和 PONG 这三种 Gossip 协议消息时使用
uint16_t count; /* Only used for some kind of messages. */
// 消息发送者的配置纪元
uint64_t currentEpoch; /* The epoch accordingly to the sending node. */
// 如果消息发送者是一个主节点,那么这里记录的是消息发送者的配置纪元
// 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的配置纪元
uint64_t configEpoch; /* The config epoch if it's a master, or the last
epoch advertised by its master if it is a
slave. */
// 节点的复制偏移量
uint64_t offset; /* Master replication offset if node is a master or
processed replication offset if node is a slave. */
// 消息发送者的名字(ID)
char sender[CLUSTER_NAMELEN]; /* Name of the sender node */
// 消息发送者目前的槽指派信息
unsigned char myslots[CLUSTER_SLOTS/8];
// 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的名字
// 如果消息发送者是一个主节点,那么这里记录的是 REDIS_NODE_NULL_NAME
// (一个 40 字节长,值全为 0 的字节数组)
char slaveof[CLUSTER_NAMELEN];
char myip[NET_IP_STR_LEN]; /* Sender IP, if not all zeroed. */
char notused1[34]; /* 34 bytes reserved for future usage. */
// 消息发送者的端口号
uint16_t cport; /* Sender TCP cluster bus port */
uint16_t flags; /* Sender node flags */
// 消息发送者所处集群的状态
unsigned char state; /* Cluster state from the POV of the sender */
// 消息标志
unsigned char mflags[3]; /* Message flags: CLUSTERMSG_FLAG[012]_... */
// 消息的正文(Body),包括 PING/PONG/UPDATE/MODULE/FAIL/PUBLISH 等类型
union clusterMsgData data;
} clusterMsg;
union clusterMsgData {
/* PING, MEET and PONG */
struct {
/* Array of N clusterMsgDataGossip structures */
// 初始化数组长度为 1,实际使用时会根据发送的节点数量动态分配内存来确定长度。
clusterMsgDataGossip gossip[1];
} ping;
/* FAIL */
struct {
clusterMsgDataFail about;
} fail;
/* PUBLISH */
struct {
clusterMsgDataPublish msg;
} publish;
/* UPDATE */
struct {
clusterMsgDataUpdate nodecfg;
} update;
/* MODULE */
struct {
clusterMsgModule msg;
} module;
};
// PING, MEET and PONG 消息采用同样的结构体
typedef struct {
char nodename[CLUSTER_NAMELEN];
uint32_t ping_sent;
uint32_t pong_received;
char ip[NET_IP_STR_LEN]; /* IP address last time it was seen */
uint16_t port; /* base port last time it was seen */
uint16_t cport; /* cluster port last time it was seen */
uint16_t flags; /* node->flags copy */
uint32_t notused1;
} clusterMsgDataGossip;
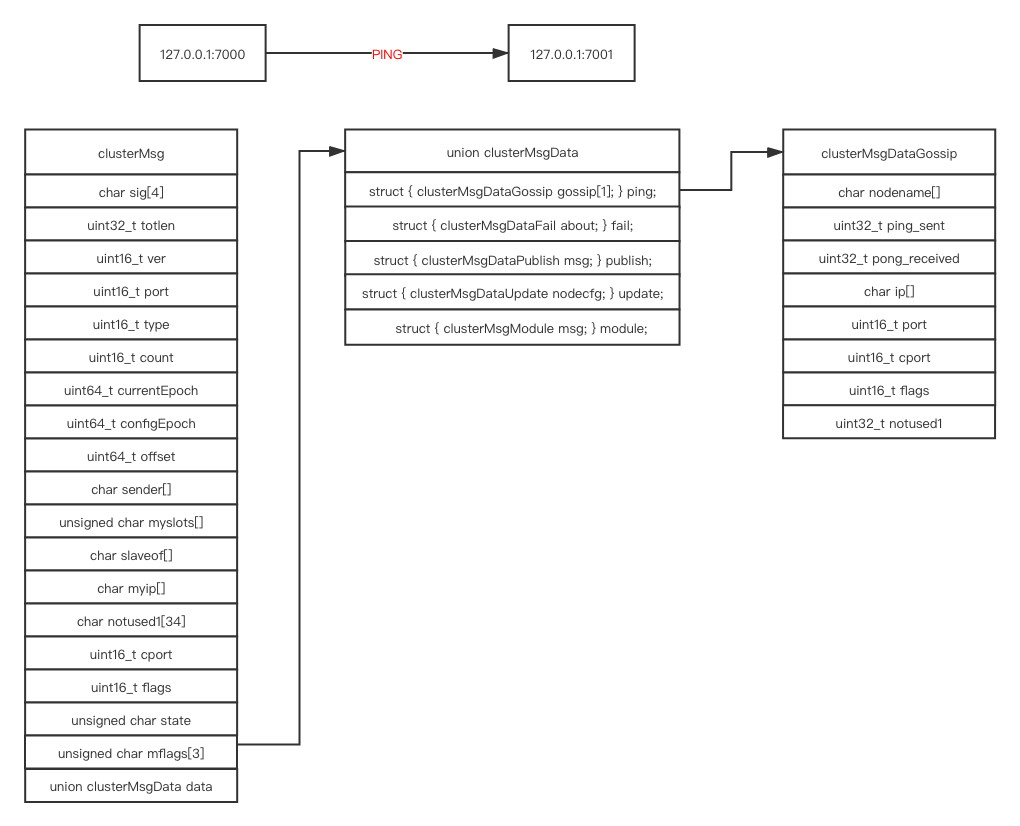
小结:
可以看到 clusterMsg(header)主要包含当前节点的信息及集群的状态数据;而 clusterMsgData (body)主要包含集群中其他节点的信息。这样在经过一定时间的传播(PING PONG MEET)后,一个节点最终会获得所有其他节点的最新状态数据。
首先触发自动 Failover 的代码在收到 GOSSIP 消息处理逻辑中,在 node 之间的连接建立时注册 handler,例如:
// cluster.c
// aeCreateFileEvent(server.el,link->fd,AE_READABLE,clusterReadHandler,link);
// clusterReadHandler 会调用 clusterProcessPacket 处理消息报文
int clusterProcessPacket(clusterLink *link) {
// 代码比较长只截取部分内容
if (type == CLUSTERMSG_TYPE_PING || type == CLUSTERMSG_TYPE_MEET) {
if (!sender && type == CLUSTERMSG_TYPE_MEET)
clusterProcessGossipSection(hdr,link);
}
if (type == CLUSTERMSG_TYPE_PING || type == CLUSTERMSG_TYPE_PONG ||
type == CLUSTERMSG_TYPE_MEET) {
/* Get info from the gossip section */
if (sender) clusterProcessGossipSection(hdr,link);
}
}
void clusterProcessGossipSection(clusterMsg *hdr, clusterLink *link) {
// header 里的 count 为消息体中的节点数量(即gossip数组大小)
uint16_t count = ntohs(hdr->count);
clusterMsgDataGossip *g = (clusterMsgDataGossip*) hdr->data.ping.gossip;
clusterNode *sender = link->node ? link->node : clusterLookupNode(hdr->sender);
// 遍历 node
while(count--) {
uint16_t flags = ntohs(g->flags);
clusterNode *node;
sds ci;
if (server.verbosity == LL_DEBUG) {
ci = representClusterNodeFlags(sdsempty(), flags);
serverLog(LL_DEBUG,"GOSSIP %.40s %s:%d@%d %s",
g->nodename,
g->ip,
ntohs(g->port),
ntohs(g->cport),
ci);
sdsfree(ci);
}
/* Update our state accordingly to the gossip sections */
node = clusterLookupNode(g->nodename);
if (node) {
/* We already know this node.
Handle failure reports, only when the sender is a master. */
// 发送方是已知的 master node
if (sender && nodeIsMaster(sender) && node != myself) {
// 从消息中的 flags 说明该节点被认为是 FAIL 或者 PFAIL 状态
if (flags & (CLUSTER_NODE_FAIL|CLUSTER_NODE_PFAIL)) {
// 把发送方添加到当前实例试视角下的该节点的故障报告列表中
if (clusterNodeAddFailureReport(node,sender)) {
serverLog(LL_VERBOSE,
"Node %.40s reported node %.40s as not reachable.",
sender->name, node->name);
}
// 检查是否要把该节点标记为 FAIL
markNodeAsFailingIfNeeded(node);
} else {
// 删除故障报告中的当前发送者,并且会检查并删除有超时的报告
// (超时的定义:当前时间-添加报告节点的时间 > 2 * cluster_node_timeout)
if (clusterNodeDelFailureReport(node,sender)) {
serverLog(LL_VERBOSE,
"Node %.40s reported node %.40s is back online.",
sender->name, node->name);
}
}
}
/* If from our POV the node is up (no failure flags are set),
* we have no pending ping for the node, nor we have failure
* reports for this node, update the last pong time with the
* one we see from the other nodes. */
// 当前节点视角下该节点没有 PFAIL/FAIL 标志,且没有待处理的 PING,并且也没有故障报告。
// 那么更新当前节点视角下该节点的 pong_received 时间为消息中的该节点的 pong_received。
//(当且仅当消息中的 pongtime 不大于当前服务器时钟+500ms 且 pongtime 大于当前节点维护的该节点的 pong_received)。
if (!(flags & (CLUSTER_NODE_FAIL|CLUSTER_NODE_PFAIL)) &&
node->ping_sent == 0 &&
clusterNodeFailureReportsCount(node) == 0)
{
mstime_t pongtime = ntohl(g->pong_received);
pongtime *= 1000; /* Convert back to milliseconds. */
/* Replace the pong time with the received one only if
* it's greater than our view but is not in the future
* (with 500 milliseconds tolerance) from the POV of our
* clock. */
if (pongtime <= (server.mstime+500) &&
pongtime > node->pong_received)
{
node->pong_received = pongtime;
}
}
/* If we already know this node, but it is not reachable, and
* we see a different address in the gossip section of a node that
* can talk with this other node, update the address, disconnect
* the old link if any, so that we'll attempt to connect with the
* new address. */
// 当前视角认为该节点是 FAIL/PFAIL 但消息中没有这样认为,且消息中节点的ip:port与当前视角不同,
// 则断开连接更新ip:port,以准备重连。
if (node->flags & (CLUSTER_NODE_FAIL|CLUSTER_NODE_PFAIL) &&
!(flags & CLUSTER_NODE_NOADDR) &&
!(flags & (CLUSTER_NODE_FAIL|CLUSTER_NODE_PFAIL)) &&
(strcasecmp(node->ip,g->ip) ||
node->port != ntohs(g->port) ||
node->cport != ntohs(g->cport)))
{
if (node->link) freeClusterLink(node->link);
memcpy(node->ip,g->ip,NET_IP_STR_LEN);
node->port = ntohs(g->port);
node->cport = ntohs(g->cport);
node->flags &= ~CLUSTER_NODE_NOADDR;
}
} else {
/* If it's not in NOADDR state and we don't have it, we
* start a handshake process against this IP/PORT pairs.
*
* Note that we require that the sender of this gossip message
* is a well known node in our cluster, otherwise we risk
* joining another cluster. */
// 非未知节点且不在黑名单,则进行握手(邀请加入集群)
if (sender &&
!(flags & CLUSTER_NODE_NOADDR) &&
!clusterBlacklistExists(g->nodename))
{
clusterStartHandshake(g->ip,ntohs(g->port),ntohs(g->cport));
}
}
/* Next node */
g++;
}
}
// 每个节点会维护自己视角下集群所有节点对应的故障报告,即保存所有认为某节点为 Fail/PFAIL 的节点列表
int clusterNodeAddFailureReport(clusterNode *failing, clusterNode *sender) {
list *l = failing->fail_reports;
listNode *ln;
listIter li;
clusterNodeFailReport *fr;
/* If a failure report from the same sender already exists, just update
* the timestamp. */
// 列表已经存在该发送方,则只更新时间戳
listRewind(l,&li);
while ((ln = listNext(&li)) != NULL) {
fr = ln->value;
if (fr->node == sender) {
fr->time = mstime();
return 0;
}
}
// 添加一个节点
/* Otherwise create a new report. */
fr = zmalloc(sizeof(*fr));
fr->node = sender;
fr->time = mstime();
listAddNodeTail(l,fr);
return 1;
}
// 根据 GOSSIP 消息中的节点数据确认是否标记为 FAIL
void markNodeAsFailingIfNeeded(clusterNode *node) {
int failures;
// quorum 集群节点数/2+1,超半数
int needed_quorum = (server.cluster->size / 2) + 1;
// nodeTimedOut 判断是否有 PFAIL 标注,没有则直接返回
if (!nodeTimedOut(node)) return; /* We can reach it. */
// 判断是否已经判断为 FAIL
if (nodeFailed(node)) return; /* Already FAILing. */
// 统计自己视角下该节点的故障报告数量
failures = clusterNodeFailureReportsCount(node);
/* Also count myself as a voter if I'm a master. */
// 自身是 master 则失败计票+1
if (nodeIsMaster(myself)) failures++;
// 计票不到半数以上,则直接返回(达不到标记 FAIL 的条件)
if (failures < needed_quorum) return; /* No weak agreement from masters. */
serverLog(LL_NOTICE,
"Marking node %.40s as failing (quorum reached).", node->name);
// 标记该节点为 FAIL
/* Mark the node as failing. */
node->flags &= ~CLUSTER_NODE_PFAIL;
node->flags |= CLUSTER_NODE_FAIL;
node->fail_time = mstime();
/* Broadcast the failing node name to everybody, forcing all the other
* reachable nodes to flag the node as FAIL. */
// 如果自己是 master,则向集群广播该节点是 FAIL 状态的消息
if (nodeIsMaster(myself)) clusterSendFail(node->name);
// 标记下个事件循环前应该执行的事件
// 这里是更新节点状态,保存配置文件
clusterDoBeforeSleep(CLUSTER_TODO_UPDATE_STATE|CLUSTER_TODO_SAVE_CONFIG);
}
前面代码是检测到 node 故障后发送 FAIL 消息,接下来看如何处理 FAIL 消息。回到 clusterProcessPacket方法,可以看到收到 FAIL 后,会对我方视角的失败节点进行 FAIL 标记:
int clusterProcessPacket(clusterLink *link) {
/.../
else if (type == CLUSTERMSG_TYPE_FAIL) {
clusterNode *failing;
if (sender) {
failing = clusterLookupNode(hdr->data.fail.about.nodename);
if (failing &&
!(failing->flags & (CLUSTER_NODE_FAIL|CLUSTER_NODE_MYSELF)))
{
serverLog(LL_NOTICE,
"FAIL message received from %.40s about %.40s",
hdr->sender, hdr->data.fail.about.nodename);
failing->flags |= CLUSTER_NODE_FAIL;
failing->fail_time = mstime();
failing->flags &= ~CLUSTER_NODE_PFAIL;
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE);
}
} else {
serverLog(LL_NOTICE,
"Ignoring FAIL message from unknown node %.40s about %.40s",
hdr->sender, hdr->data.fail.about.nodename);
}
}
/...
}
故障转移
通过 Gossip 消息不断传播,最终大部分节点会收到携带 FAIL 节点的消息。接下来看 FAIL 节点的从节点完成主从切换的过程。
触发切换的逻辑在 clusterCron 循环中,每一个 slave 都会调用 clusterHandleSlaveFailover :
/* This is executed 10 times every second */
void clusterCron(void) {
/.../
if (nodeIsSlave(myself)) {
clusterHandleManualFailover();
// 判断是否关闭 Failover
if (!(server.cluster_module_flags & CLUSTER_MODULE_FLAG_NO_FAILOVER))
//
clusterHandleSlaveFailover();
/* If there are orphaned slaves, and we are a slave among the masters
* with the max number of non-failing slaves, consider migrating to
* the orphaned masters. Note that it does not make sense to try
* a migration if there is no master with at least *two* working
* slaves. */
// 如果存在孤立master(没有 slave 但是分配了 slot)并且集群中 max_slaves 大于等于2,且正好当前节点属于拥有 max slaves 的 master 的 salve,
// 那就进行从节点迁移,也就是把当前节点置为某孤立主节点的从节点
if (orphaned_masters && max_slaves >= 2 && this_slaves == max_slaves)
clusterHandleSlaveMigration(max_slaves);
}
}
void clusterHandleSlaveFailover(void) {
mstime_t data_age;
mstime_t auth_age = mstime() - server.cluster->failover_auth_time;
int needed_quorum = (server.cluster->size / 2) + 1;
int manual_failover = server.cluster->mf_end != 0 &&
server.cluster->mf_can_start;
mstime_t auth_timeout, auth_retry_time;
server.cluster->todo_before_sleep &= ~CLUSTER_TODO_HANDLE_FAILOVER;
/* Compute the failover timeout (the max time we have to send votes
* and wait for replies), and the failover retry time (the time to wait
* before trying to get voted again).
*
* Timeout is MAX(NODE_TIMEOUT*2,2000) milliseconds.
* Retry is two times the Timeout.
*/
auth_timeout = server.cluster_node_timeout*2;
if (auth_timeout < 2000) auth_timeout = 2000;
auth_retry_time = auth_timeout*2;
/* Pre conditions to run the function, that must be met both in case
* of an automatic or manual failover:
* 1) We are a slave.
* 2) Our master is flagged as FAIL, or this is a manual failover.
* 3) We don't have the no failover configuration set, and this is
* not a manual failover.
* 4) It is serving slots. */
// 满足这些条件则才进行 failover
// 1. 当前节点是 master
// 2. 节点的 master 节点需标记为 FAIL(手动 failover 除外)
// 3. 没有配置从节点不进行 failover(手动 failover 除外)
// 4. master 节点分配了 slots
if (nodeIsMaster(myself) ||
myself->slaveof == NULL ||
(!nodeFailed(myself->slaveof) && !manual_failover) ||
(server.cluster_slave_no_failover && !manual_failover) ||
myself->slaveof->numslots == 0)
{
/* There are no reasons to failover, so we set the reason why we
* are returning without failing over to NONE. */
// 标记本次不进行 failover 的原因
server.cluster->cant_failover_reason = CLUSTER_CANT_FAILOVER_NONE;
return;
}
/* Set data_age to the number of seconds we are disconnected from
* the master. */
// 记录和 master 最近的数据复制的时间间隔,用来表示当前节点数据的新旧程度
if (server.repl_state == REPL_STATE_CONNECTED) {
data_age = (mstime_t)(server.unixtime - server.master->lastinteraction)
* 1000;
} else {
data_age = (mstime_t)(server.unixtime - server.repl_down_since) * 1000;
}
/* Remove the node timeout from the data age as it is fine that we are
* disconnected from our master at least for the time it was down to be
* flagged as FAIL, that's the baseline. */
// 时间间隔扣去 cluster_node_timeout (cluster_node_timeout 时间是合理的,剩下的时间作为判断的依据)
if (data_age > server.cluster_node_timeout)
data_age -= server.cluster_node_timeout;
/* Check if our data is recent enough according to the slave validity
* factor configured by the user.
*
* Check bypassed for manual failovers. */
//
// 如果当前服务配置了 cluster_slave_validity_factor(从节点有效因子),
// 那么判断 data_age 是否超过了规定的时间,超过就表示当前从节点复制的数据太旧,不具备进行 Failover 的条件,直接返回。
if (server.cluster_slave_validity_factor &&
data_age >
(((mstime_t)server.repl_ping_slave_period * 1000) +
(server.cluster_node_timeout * server.cluster_slave_validity_factor)))
{
if (!manual_failover) {
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_DATA_AGE);
return;
}
}
/* If the previous failover attempt timedout and the retry time has
* elapsed, we can setup a new one. */
// 距离上次选举时间大于 auth_retry_time,说明可以发起新的 failover 了。
// 下面主要是记录一些本次 failover 的属性
if (auth_age > auth_retry_time) {
server.cluster->failover_auth_time = mstime() +
500 + /* Fixed delay of 500 milliseconds, let FAIL msg propagate. */
random() % 500; /* Random delay between 0 and 500 milliseconds. */
server.cluster->failover_auth_count = 0;
server.cluster->failover_auth_sent = 0;
server.cluster->failover_auth_rank = clusterGetSlaveRank();
/* We add another delay that is proportional to the slave rank.
* Specifically 1 second * rank. This way slaves that have a probably
* less updated replication offset, are penalized. */
server.cluster->failover_auth_time +=
server.cluster->failover_auth_rank * 1000;
/* However if this is a manual failover, no delay is needed. */
if (server.cluster->mf_end) {
server.cluster->failover_auth_time = mstime();
server.cluster->failover_auth_rank = 0;
}
serverLog(LL_WARNING,
"Start of election delayed for %lld milliseconds "
"(rank #%d, offset %lld).",
server.cluster->failover_auth_time - mstime(),
server.cluster->failover_auth_rank,
replicationGetSlaveOffset());
/* Now that we have a scheduled election, broadcast our offset
* to all the other slaves so that they'll updated their offsets
* if our offset is better. */
// 发送 PONG 消息给所有从节点(拥有和当前 slave 同一个 master 的 slave 们)
// 目的是发送当前节点的复制 offset,如果其他节点 offset 比当前的小则会进行更新
clusterBroadcastPong(CLUSTER_BROADCAST_LOCAL_SLAVES);
return;
}
/* It is possible that we received more updated offsets from other
* slaves for the same master since we computed our election delay.
* Update the delay if our rank changed.
*
* Not performed if this is a manual failover. */
// failover_auth_sent == 0 说明投票未开始
if (server.cluster->failover_auth_sent == 0 &&
server.cluster->mf_end == 0)
{
// 获得当前节点的排名,排名比较的是当前节点主节点的所有从节点的复制偏移量,偏移量越大说明数据越接近master,则rank越小(越靠前,最小0)。
int newrank = clusterGetSlaveRank();
// 新 rank 比之前更大了,说明比当前节点更新的 slave
if (newrank > server.cluster->failover_auth_rank) {
// 增加故障转移投票发起时间
long long added_delay =
(newrank - server.cluster->failover_auth_rank) * 1000;
server.cluster->failover_auth_time += added_delay;
server.cluster->failover_auth_rank = newrank;
serverLog(LL_WARNING,
"Replica rank updated to #%d, added %lld milliseconds of delay.",
newrank, added_delay);
}
}
/* Return ASAP if we can't still start the election. */
// 选举时间没到,返回
if (mstime() < server.cluster->failover_auth_time) {
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_WAITING_DELAY);
return;
}
/* Return ASAP if the election is too old to be valid. */
// 距离选举时间超过 auth_timeout ,返回
if (auth_age > auth_timeout) {
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_EXPIRED);
return;
}
/* Ask for votes if needed. */
// 发起 failover 投票
if (server.cluster->failover_auth_sent == 0) {
// 当前纪元自增
server.cluster->currentEpoch++;
server.cluster->failover_auth_epoch = server.cluster->currentEpoch;
serverLog(LL_WARNING,"Starting a failover election for epoch %llu.",
(unsigned long long) server.cluster->currentEpoch);
clusterRequestFailoverAuth();
server.cluster->failover_auth_sent = 1;
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE|
CLUSTER_TODO_FSYNC_CONFIG);
return; /* Wait for replies. */
}
/* Check if we reached the quorum. */
// 当前节点收到票数过半,则可以成为新的 master
if (server.cluster->failover_auth_count >= needed_quorum) {
/* We have the quorum, we can finally failover the master. */
serverLog(LL_WARNING,
"Failover election won: I'm the new master.");
/* Update my configEpoch to the epoch of the election. */
// 更新节点的 configEpoch
if (myself->configEpoch < server.cluster->failover_auth_epoch) {
myself->configEpoch = server.cluster->failover_auth_epoch;
serverLog(LL_WARNING,
"configEpoch set to %llu after successful failover",
(unsigned long long) myself->configEpoch);
}
/* Take responsibility for the cluster slots. */
clusterFailoverReplaceYourMaster();
} else {
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_WAITING_VOTES);
}
}
Failover 的最后阶段,替换 master:
void clusterFailoverReplaceYourMaster(void) {
int j;
clusterNode *oldmaster = myself->slaveof;
if (nodeIsMaster(myself) || oldmaster == NULL) return;
/* 1) Turn this node into a master. */
// 修改配置把当前节点改为主节点
clusterSetNodeAsMaster(myself);
// 取消复制操作
replicationUnsetMaster();
/* 2) Claim all the slots assigned to our master. */
// 把原 master 负责的 slot 分配给自己
for (j = 0; j < CLUSTER_SLOTS; j++) {
if (clusterNodeGetSlotBit(oldmaster,j)) {
clusterDelSlot(j);
clusterAddSlot(myself,j);
}
}
/* 3) Update state and save config. */
clusterUpdateState();
clusterSaveConfigOrDie(1);
/* 4) Pong all the other nodes so that they can update the state
* accordingly and detect that we switched to master role. */
// 广播 PONG 消息给其他所有节点,以便其他节点能够更新状态
clusterBroadcastPong(CLUSTER_BROADCAST_ALL);
/* 5) If there was a manual failover in progress, clear the state. */
resetManualFailover();
}
以上是发起 Failover 和切换主节点的过程,还少一步投票的过程,以下继续:
// 本方法广播发送 CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 消息来发起集群节点进行投票
void clusterRequestFailoverAuth(void) {
unsigned char buf[sizeof(clusterMsg)];
clusterMsg *hdr = (clusterMsg*) buf;
uint32_t totlen;
clusterBuildMessageHdr(hdr,CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST);
/* If this is a manual failover, set the CLUSTERMSG_FLAG0_FORCEACK bit
* in the header to communicate the nodes receiving the message that
* they should authorized the failover even if the master is working. */
if (server.cluster->mf_end) hdr->mflags[0] |= CLUSTERMSG_FLAG0_FORCEACK;
totlen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
hdr->totlen = htonl(totlen);
clusterBroadcastMessage(buf,totlen);
}
// 其他节点收到 CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 消息后,会调用:
// 入参 node:sender request:msg
void clusterSendFailoverAuthIfNeeded(clusterNode *node, clusterMsg *request) {
clusterNode *master = node->slaveof;
uint64_t requestCurrentEpoch = ntohu64(request->currentEpoch);
uint64_t requestConfigEpoch = ntohu64(request->configEpoch);
unsigned char *claimed_slots = request->myslots;
int force_ack = request->mflags[0] & CLUSTERMSG_FLAG0_FORCEACK;
int j;
/* IF we are not a master serving at least 1 slot, we don't have the
* right to vote, as the cluster size in Redis Cluster is the number
* of masters serving at least one slot, and quorum is the cluster
* size + 1 */
// 只有分配了槽位的 master 节点才有资格参与投票,原因是集群的法定人数(quorum)是根据集群携带槽位的master数量+1来定义的。
if (nodeIsSlave(myself) || myself->numslots == 0) return;
/* Request epoch must be >= our currentEpoch.
* Note that it is impossible for it to actually be greater since
* our currentEpoch was updated as a side effect of receiving this
* request, if the request epoch was greater. */
// 消息纪元小于当前节点,则不处理。因为消息里的纪元小说明可能是发送方很长一段时间没有上线导致版本落后,所以不处理其请求。
if (requestCurrentEpoch < server.cluster->currentEpoch) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: reqEpoch (%llu) < curEpoch(%llu)",
node->name,
(unsigned long long) requestCurrentEpoch,
(unsigned long long) server.cluster->currentEpoch);
return;
}
/* I already voted for this epoch? Return ASAP. */
// 我已经为本次选举投过票了,(通过对比上次投票的纪元判断)
if (server.cluster->lastVoteEpoch == server.cluster->currentEpoch) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: already voted for epoch %llu",
node->name,
(unsigned long long) server.cluster->currentEpoch);
return;
}
/* Node must be a slave and its master down.
* The master can be non failing if the request is flagged
* with CLUSTERMSG_FLAG0_FORCEACK (manual failover). */
// sender 必须是 slave 并且其 master 已知,或是手动 failover
if (nodeIsMaster(node) || master == NULL ||
(!nodeFailed(master) && !force_ack))
{
if (nodeIsMaster(node)) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: it is a master node",
node->name);
} else if (master == NULL) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: I don't know its master",
node->name);
} else if (!nodeFailed(master)) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: its master is up",
node->name);
}
return;
}
/* We did not voted for a slave about this master for two
* times the node timeout. This is not strictly needed for correctness
* of the algorithm but makes the base case more linear. */
// 控制对同一个节点投票时间间隔
if (mstime() - node->slaveof->voted_time < server.cluster_node_timeout * 2)
{
serverLog(LL_WARNING,
"Failover auth denied to %.40s: "
"can't vote about this master before %lld milliseconds",
node->name,
(long long) ((server.cluster_node_timeout*2)-
(mstime() - node->slaveof->voted_time)));
return;
}
/* The slave requesting the vote must have a configEpoch for the claimed
* slots that is >= the one of the masters currently serving the same
* slots in the current configuration. */
// 对于 sender 声明其所负责的每个 slot 中,存在当前节点视角下某个 slot 的配置纪元大于请求纪元,
// 那么说明 sender 的配置纪元已经过期,拒绝给它投票。
for (j = 0; j < CLUSTER_SLOTS; j++) {
if (bitmapTestBit(claimed_slots, j) == 0) continue;
if (server.cluster->slots[j] == NULL ||
server.cluster->slots[j]->configEpoch <= requestConfigEpoch)
{
continue;
}
/* If we reached this point we found a slot that in our current slots
* is served by a master with a greater configEpoch than the one claimed
* by the slave requesting our vote. Refuse to vote for this slave. */
serverLog(LL_WARNING,
"Failover auth denied to %.40s: "
"slot %d epoch (%llu) > reqEpoch (%llu)",
node->name, j,
(unsigned long long) server.cluster->slots[j]->configEpoch,
(unsigned long long) requestConfigEpoch);
return;
}
/* We can vote for this slave. */
// 决定投票给该 slave。
server.cluster->lastVoteEpoch = server.cluster->currentEpoch;
node->slaveof->voted_time = mstime();
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|CLUSTER_TODO_FSYNC_CONFIG);
// 发送一个 CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 消息,答复给 sender node,表达同意给它投票。
clusterSendFailoverAuth(node);
serverLog(LL_WARNING, "Failover auth granted to %.40s for epoch %llu",
node->name, (unsigned long long) server.cluster->currentEpoch);
}
int clusterProcessPacket(clusterLink *link) {
...
// 收到 CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK
else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK) {
if (!sender) return 1; /* We don't know that node. */
/* We consider this vote only if the sender is a master serving
* a non zero number of slots, and its currentEpoch is greater or
* equal to epoch where this node started the election. */
// 只处理负责 slot 的 master 节点发送的 ack,且对方的 currentEpoch 需要大于当前节点发起投票的配置纪元
if (nodeIsMaster(sender) && sender->numslots > 0 &&
senderCurrentEpoch >= server.cluster->failover_auth_epoch)
{
// 节点获得的投票数+1
server.cluster->failover_auth_count++;
/* Maybe we reached a quorum here, set a flag to make sure
* we check ASAP. */
// 标记 CLUSTER_TODO_HANDLE_FAILOVER,使得在下一次事件循环前,进行投票统计是否达到 quorum、执行 Failover
// 在 clusterCron 循环和 clusterBeforeSleep 循环中都会执行 clusterHandleSlaveFailover
clusterDoBeforeSleep(CLUSTER_TODO_HANDLE_FAILOVER);
}
}
}
自此完成 Slave Failover Master 的全过程。
客户端感知 Failover
经过以上流程,Redis Cluster 发生故障后,集群的拓扑结构发生了变化。那么客户端如果仍然对故障节点进行读写操作,必然会出现异常。那么应该如何应对呢?
一般有几种策略:
- 主动轮询
客户端发起定时任务,与 Redis Cluster 保持“心跳”,获取集群的状态和拓扑结构,并且保持同步。当集群发生变化时,刷新客户端缓存的集群信息,重建连接。
-
被动重试
当集群发生故障,客户端捕获异常(重试若干次)后,查询集群状态和拓扑结构刷新自己的缓存或是重试其他节点,利用 Redis Cluster 的重定向错误定位新节点,刷新客户端缓存,重建连接。
例如,Jedis / Lettuce 都支持主动查询(通过CLUSTER NODES 命令)和被动重试机制,以支持 Redis Cluster Failover 后客户端能够及时感知。
总结
自动 Failover 过程可以分为两个阶段:
- 故障检测
- 主观故障检测:每个节点会对 PING 超时(超过 cluster_node_timeout)的节点标记疑似下线状态(Probable Fail,PFAIL)
- 客观故障检测:每个节点统计集群中所有主节点发送的 PFAIL 节点消息,若本节点视角下集群过半主节点将某节点标记 PFAIL,且本节点对某节点标记为了 PFAIL,那么标记其为客观下线(FAIL)。如果当前节点是主节点,还会对节点 FAIL 的消息进行集群广播。
- 选举及故障转移
- 从节点发起选举:当 FAIL 节点的从节点感知到自己的 master 状态时,会广播投票消息来拉票,请求所有具备投票权的节点给自己投票(这些节点必须是 master 且必须对某些 slot 负责)。
- 拉票过程:拉票并不是立即执行的,由于 master 可能有多个 slave,所以 slave 感知到 master FAIL 时会进行优先级排序,以自己的主从复制偏移量作为排序依据,排序越高说明和 master 数据越接近,则会先发起拉票(先拉票则成为 master 的可能性越大),排序越低的则发起拉票的时间会相应延迟一段时间。
- 主节点投票:主节点会给从节点响应 ACK 来进行投票,对应的从节点收到后会进行票数统计。
- 计票并完成主从切换:在所有发起投票的从节点中,得票超过半数主节点的从节点有资格成为新 master,并接管原 master,并向集群所有节点广播这个天大的消息。(若没有从节点得票过半,那就会重新进行下轮选举,直到选出新节点为止)。