
文章目录
主从
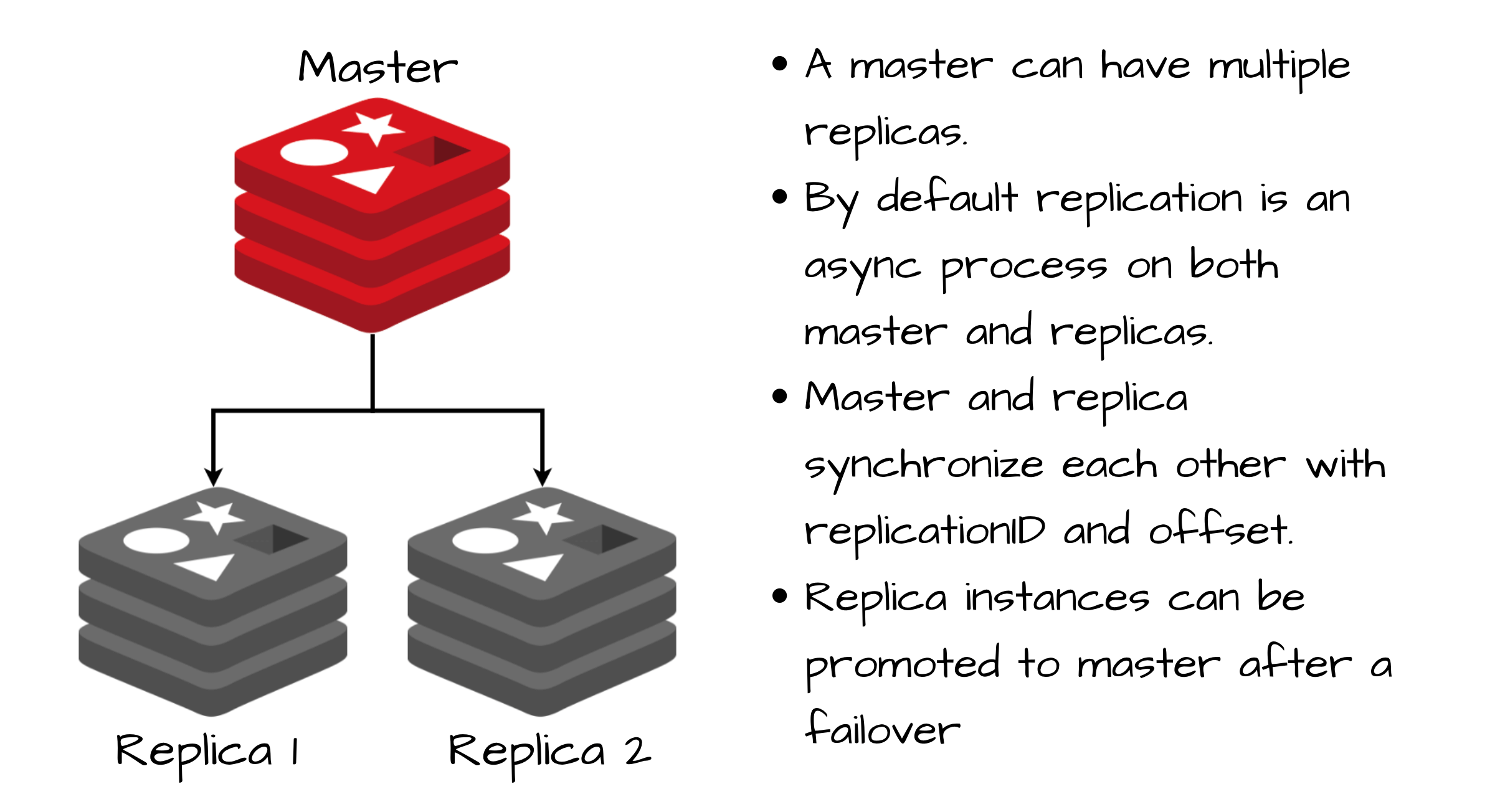
主从架构提供读写分离的能力。
- 写操作:只在主库执行,之后将写操作同步到从库;
- 读操作:主、从库都可以执行;
主从复制解决或缓解了数据冗余、故障恢复、读负载均衡等问题,但其缺陷仍很明显:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
主从复制是其他高可用架构的基础。
主从复制过程
启动多个Redis实例的时候,它们相互之间可以通过 replicaof命令(Redis 5.0 之前用 slaveof)形成主从关系。
replicaof <redis master IP>
复制过程是异步的,分为全量同步和增量同步(redis 2.8 后增加了增量同步机制)。
只有从节点第一次连接上主节点是全量同步,断线重连有可能触发全量同步也有可能是增量同步(master 判断 runid 是否一致),除此之外的情况都是增量同步。
几个名词:
运行 ID (runid):每个 Redis server 都会有自己的运行 ID,由 40 个随机的十六进制字符组成。当 slave 初次复制 master 时,master 会将自己的运行 ID 发给 slave 进行保存,这样 slave 重连时再将这个运行 ID 发送给重连上的 master ,master 会接受这个 ID 并与自身的运行 ID 比较进而判断是否是同一个 master。
复制偏移量 (offset):执行主从复制的双方都会分别维护一个复制偏移量,master 每次向 slave 传播 N 个字节,自己的复制偏移量就增加 N;同理 slave 接收 N 个字节,复制偏移量也增加 N。通过对比主从之间的复制偏移量就可以知道主从间的同步状态。
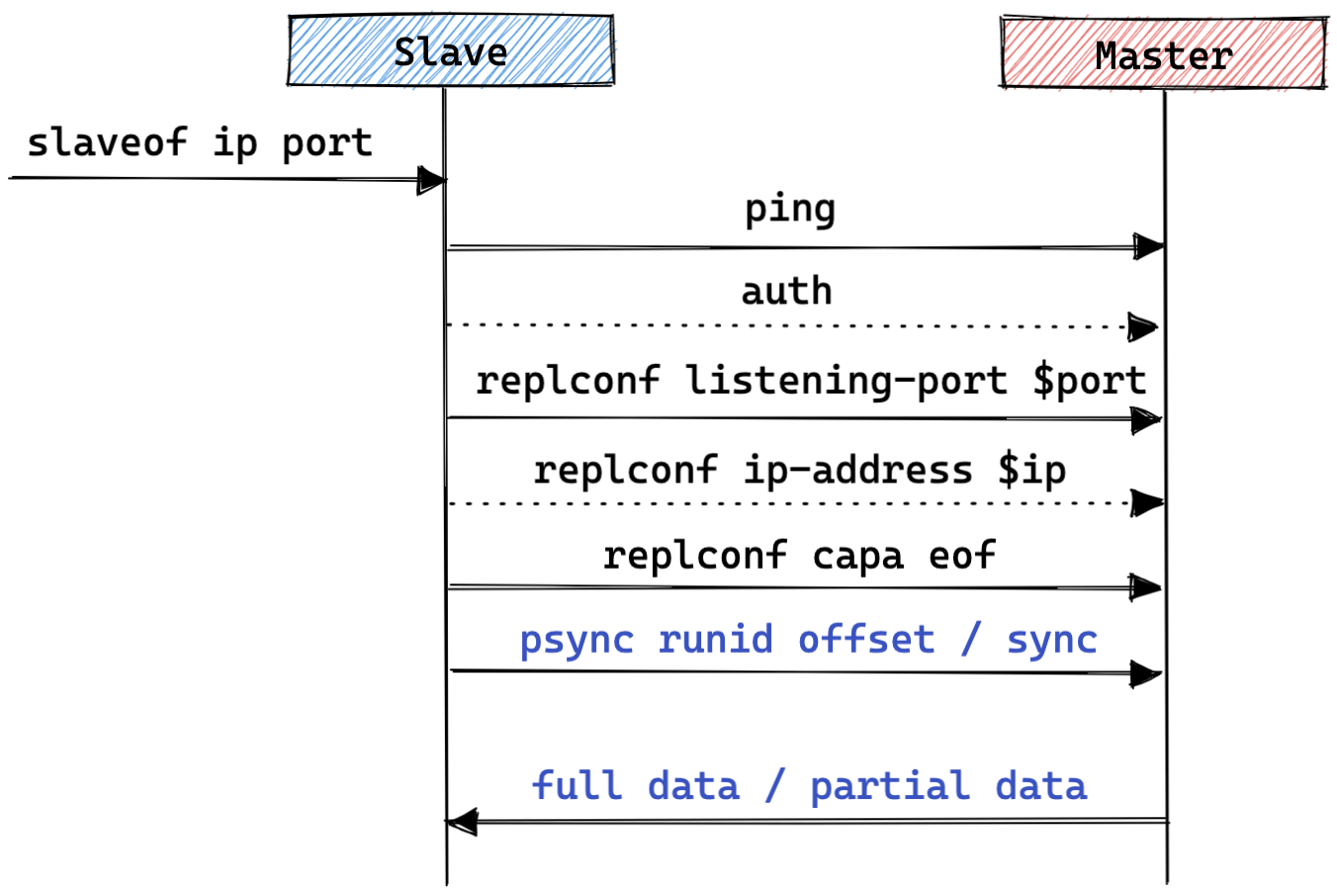
执行 replicaof 命令的同步过程如下:
- slave 请求全量同步:
- slave 通过
PSYNCrunid offset 命令,将正在复制的 runid 和 offset 发送给 master。 - 由于是初次复制,自然是没有 runid 和 offset 的,此时会发送<?,-1>,因此将执行全量同步。
- master 响应
FULLRESYNC并携带 master 的 runid 和 offset,slave 收到后会记录这两个值。
- slave 通过
- master 同步全量数据给 slave:
- master 执行
bgsave来生成 RDB 文件,然后把文件发送给从服务器。(这个过程不会阻塞主线程,master 通过 fork 子进程生成 RDB 文件,同时会使用一个缓冲区记录从现在开始执行的所有写命令,用于记录 slave load 完 RDB 文件之前 master 产生的写命令。) - 从服务器收到 RDB 文件后,会先清空当前的数据,然后载入 RDB 文件。
- master 执行
- master 同步增量数据给 slave:
- slave 完成 RDB 的载入后,会回复一个确认消息给 master。
- 之后 master 会将 replication buffer 缓冲区里所记录的写操作命令发送给 slave ,slave 来自master 的 replication buffer 缓冲区里发来的命令,这时主从数据就一致了。
以上完成主从初次同步,双方就会维护一个 TCP 长连接,接下来 master 会利用这个连接不断异步传播命令给 slave(Redis 主节点每次收到写命令之后,先写到内部的缓冲区,然后异步发送给从节点。),slave 执行这些命令使得主从数据保持一致。
另外 Redis 4.0 加入无盘复制机制,指的是 master fork 子进程执行
bgsave来生成 RDB 文件阶段不再落盘,而是一边 dump 数据一边发送给 slave,减少了磁盘的读写过程。Redis 6.0 实现 slave 无盘加载,即对收到的 RDB 直接加载而不再经过磁盘。
主从架构下,过期 Key 的处理方式:
主节点处理了一个 key 或者通过淘汰算法淘汰了一个 key,这个时间主节点模拟一条 del 命令发送给从节点,从节点收到该命令后,就进行删除key的操作。
Redis Sentinel
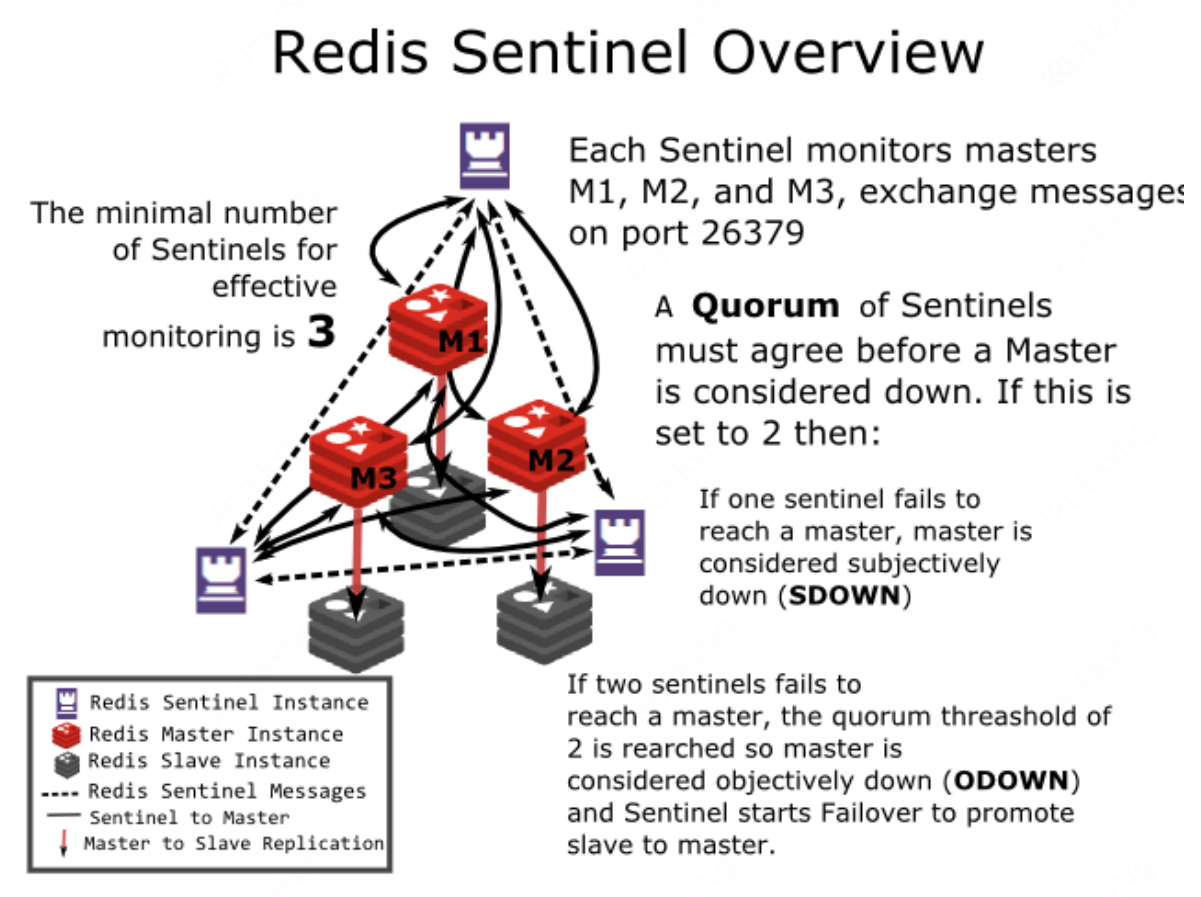
引入 Sentinel 进程对 Redis 实例(主节点、从节点)运行状态的监控,并能够在主节点发生故障时通过一系列的机制实现选主及主从切换,实现故障转移,确保整个 Redis 集群的可用性。
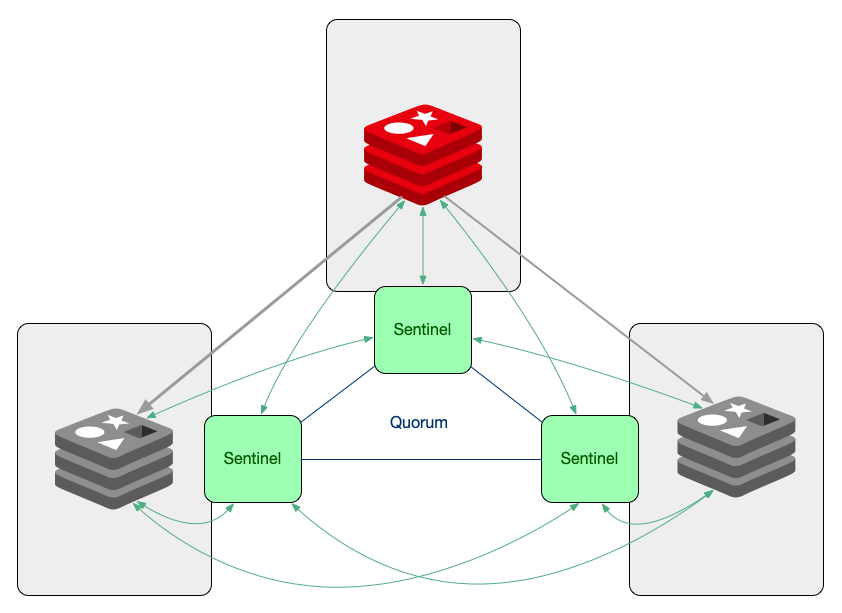
Sentinel 作用:
- 监控:持续监控 master 、slave 是否处于预期工作状态。
- 自动切换主库:当 Master 运行故障,哨兵启动自动故障恢复流程:从 slave 中选择一台作为新 master。
- 通知:让 slave 执行 replicaof ,与新的 master 同步;并且通知客户端与新 master 建立连接。
Twemproxy
Twitter 开源的基于 C 语言开发的轻量级 Redis 集群解决方案,实现请求路由转发到集群对应的分片,既可以做Redis Proxy,还可以做Memcached Proxy。路由算法包括一致性hash(默认)、hash、random。
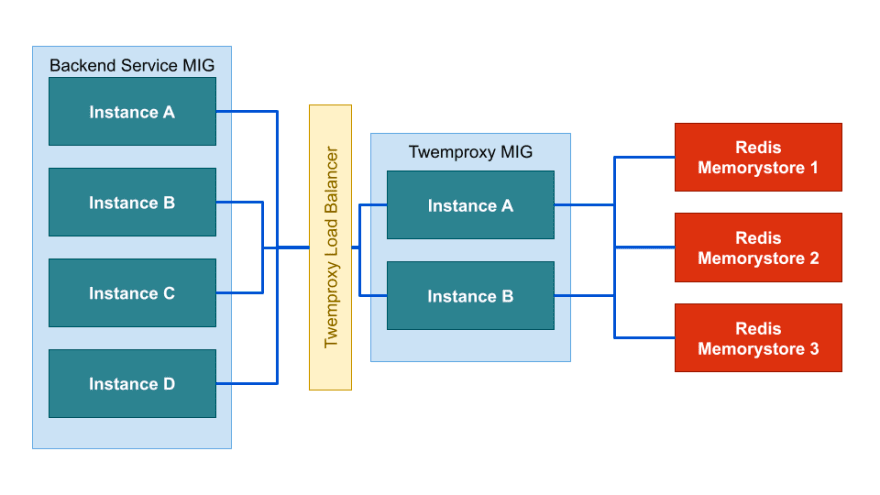
缺点是无法在线扩容、缩容,需要重启处理。
Codis
https://github.com/CodisLabs/codis
Codis 是豌豆荚团队开源,基于 Go 语言开发,在 Redis Cluster 之前就发布的代理式 Redis 集群解决方案。
- 架构:
- codis 1.x – codis 2.x
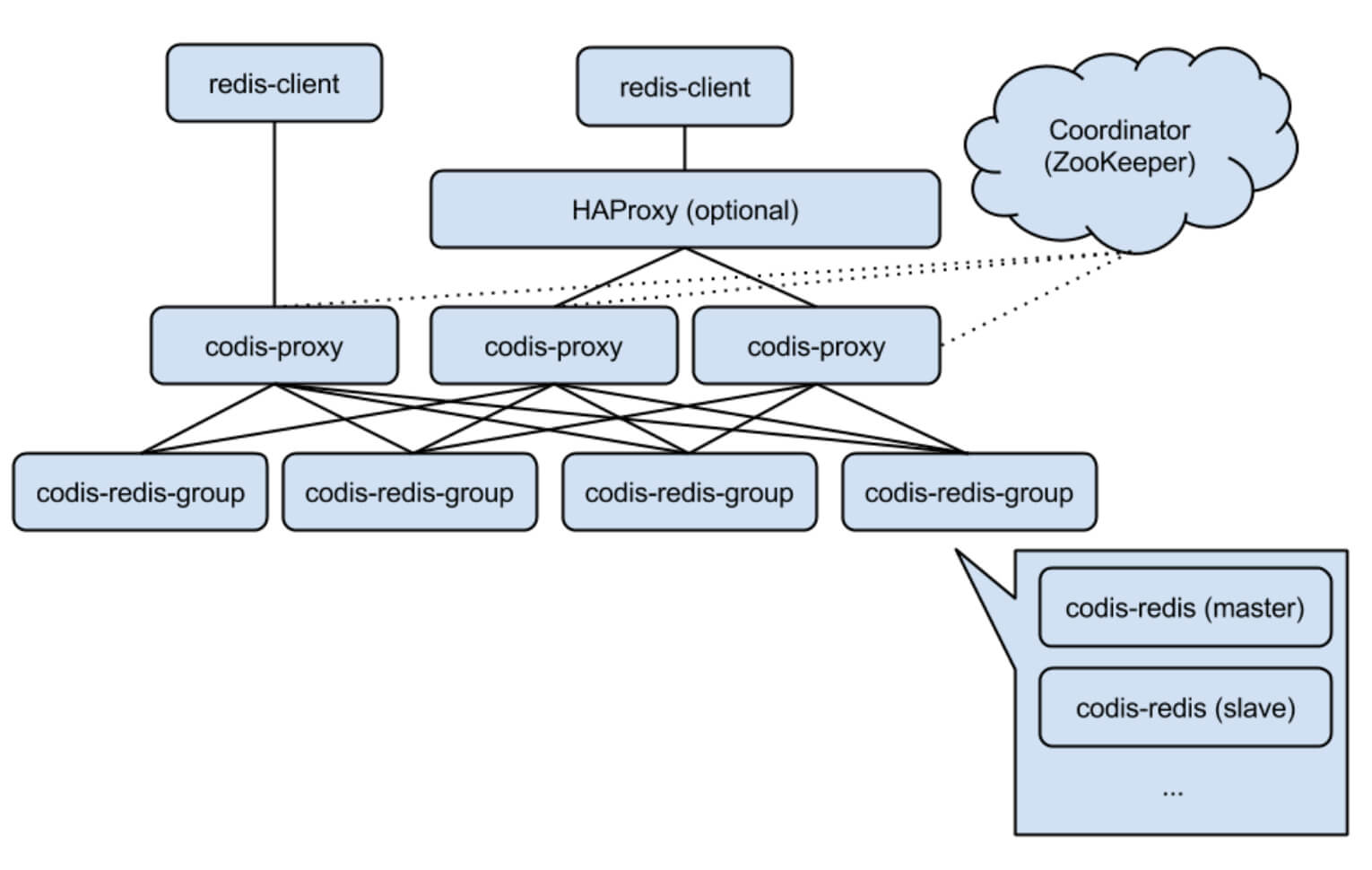
- Codis Proxy (codis-proxy)
- 实现了Redis协议,表现的和原生Redis差不多,集群部署,无状态,会从zk同步节点的槽位分布路由信息
- Codis Manager (codis-config)
- 管理工具,节点的增删改查
- Codis Redis (codis-server)
- ZooKeeper
- 存放数据路由表,proxy 元数据,config 通过 zookeeper 下发配置到每个proxy
- Codis Proxy (codis-proxy)
- codis 3.x
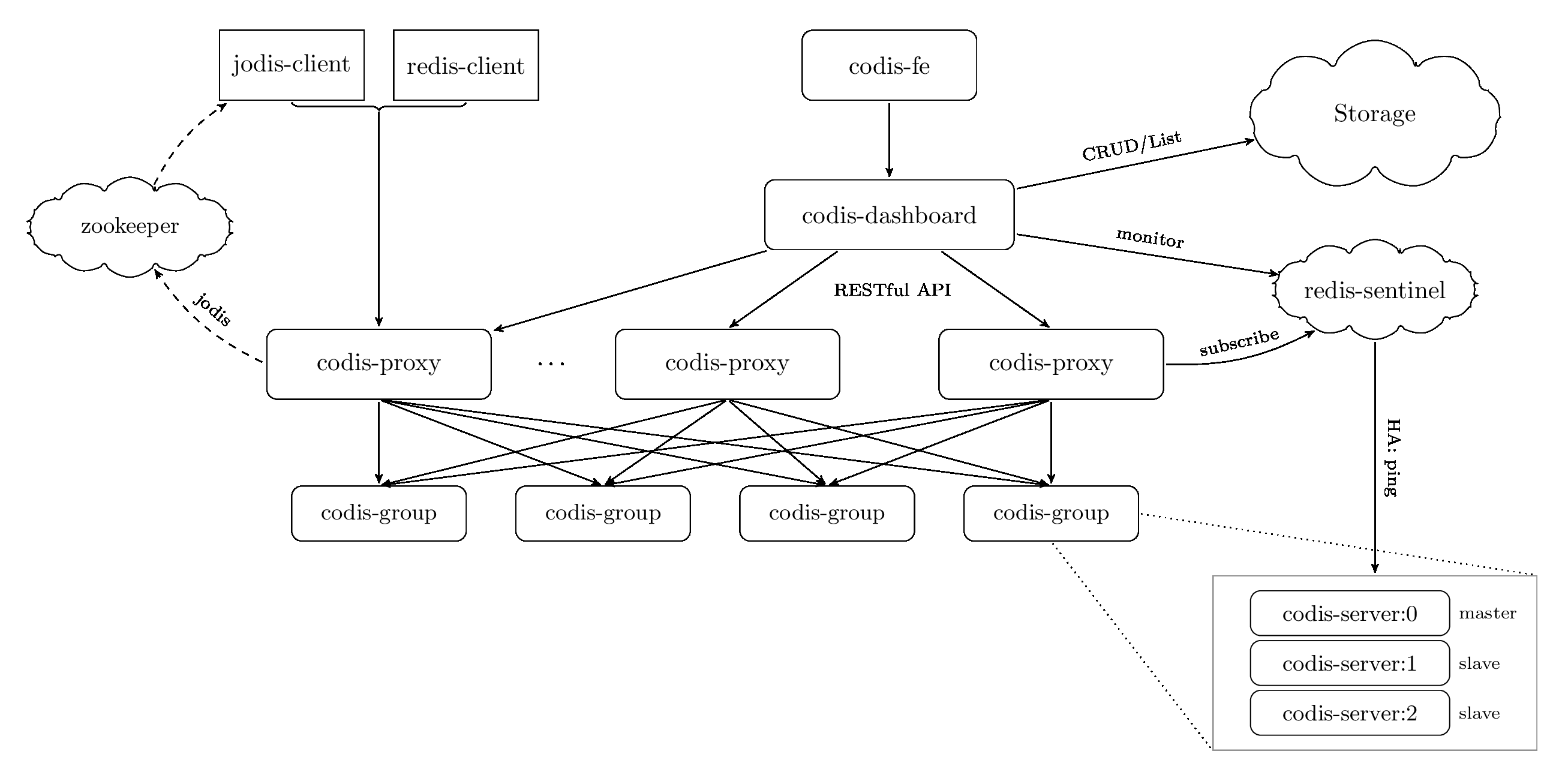
- Codis Server:基于 redis-3.2.8 分支开发。增加了额外的数据结构,以支持 slot 有关的操作以及数据迁移指令。具体的修改可以参考文档 redis 的修改。
- Codis Proxy:客户端连接的 Redis 代理服务, 实现了 Redis 协议。 除部分命令不支持以外(不支持的命令列表),表现的和原生的 Redis 没有区别(就像 Twemproxy)。
- 对于同一个业务集群而言,可以同时部署多个 codis-proxy 实例;
- 不同 codis-proxy 之间由 codis-dashboard 保证状态同步。
- Codis Dashboard:集群管理工具,支持 codis-proxy、codis-server 的添加、删除,以及据迁移等操作。在集群状态发生改变时,codis-dashboard 维护集群下所有 codis-proxy 的状态的一致性。
- 对于同一个业务集群而言,同一个时刻 codis-dashboard 只能有 0个或者1个;
- 所有对集群的修改都必须通过 codis-dashboard 完成。
- Codis Admin:集群管理的命令行工具。
- 可用于控制 codis-proxy、codis-dashboard 状态以及访问外部存储。
- Codis FE:集群管理界面。
- 多个集群实例共享可以共享同一个前端展示页面;
- 通过配置文件管理后端 codis-dashboard 列表,配置文件可自动更新。
- Storage:为集群状态提供外部存储。
- 提供 Namespace 概念,不同集群的会按照不同 product name 进行组织;
- 目前仅提供了 Zookeeper、Etcd、Fs 三种实现,但是提供了抽象的 interface 可自行扩展。
相比于 2.x 的优化:
- 解耦 proxy 和 zk,元数据保存支持 zk、etcd、filesystem…
- 基于 redis-sentinel 实现主备自动切换
- proxy 支持读写分离、优先读同 IP/同 DC 下副本功能
- codis 1.x – codis 2.x
- 能力
- 不停机扩容/缩容,增减 redis 实例对 client 完全透明、不需要重启服务(如果请求的 key 位于迁移中的 slot,Codis 会立即强制对当前的 key 进行单个迁移,迁移完成后,将请求转发给新的Redis实例)
- Codis 提供自动均衡,能够均衡各节点 slot 数量,自动迁移数据
- 完全兼容 Twemproxy
- 缺点
- 要想使用 proxy 的 HA 必须使用定制客户端 jodis
- 强依赖zk,会出现zk死机或选举阶段服务不可用或者通信问题,zk没有及时摘除故障proxy,导致请求按比例丢失的风险
- 缩/扩容困难,需要手动干预
- 不支持发布订阅等部分命令
- 组件多,部署复杂
Redis Cluster
Redis 官方集群方案,基于 smart client 和去中心的设计,客户端上缓存路由表,并且 Redis Cluster 的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的 Slot(16384个 Slot ,2^14),通过Gossip协议实现各节点最终一致。
相比基于 Proxy 的中心化方案,需要实现 Proxy 本身的高可用,并且增加一层Proxy进行转发,必然会有一定的性能损耗。
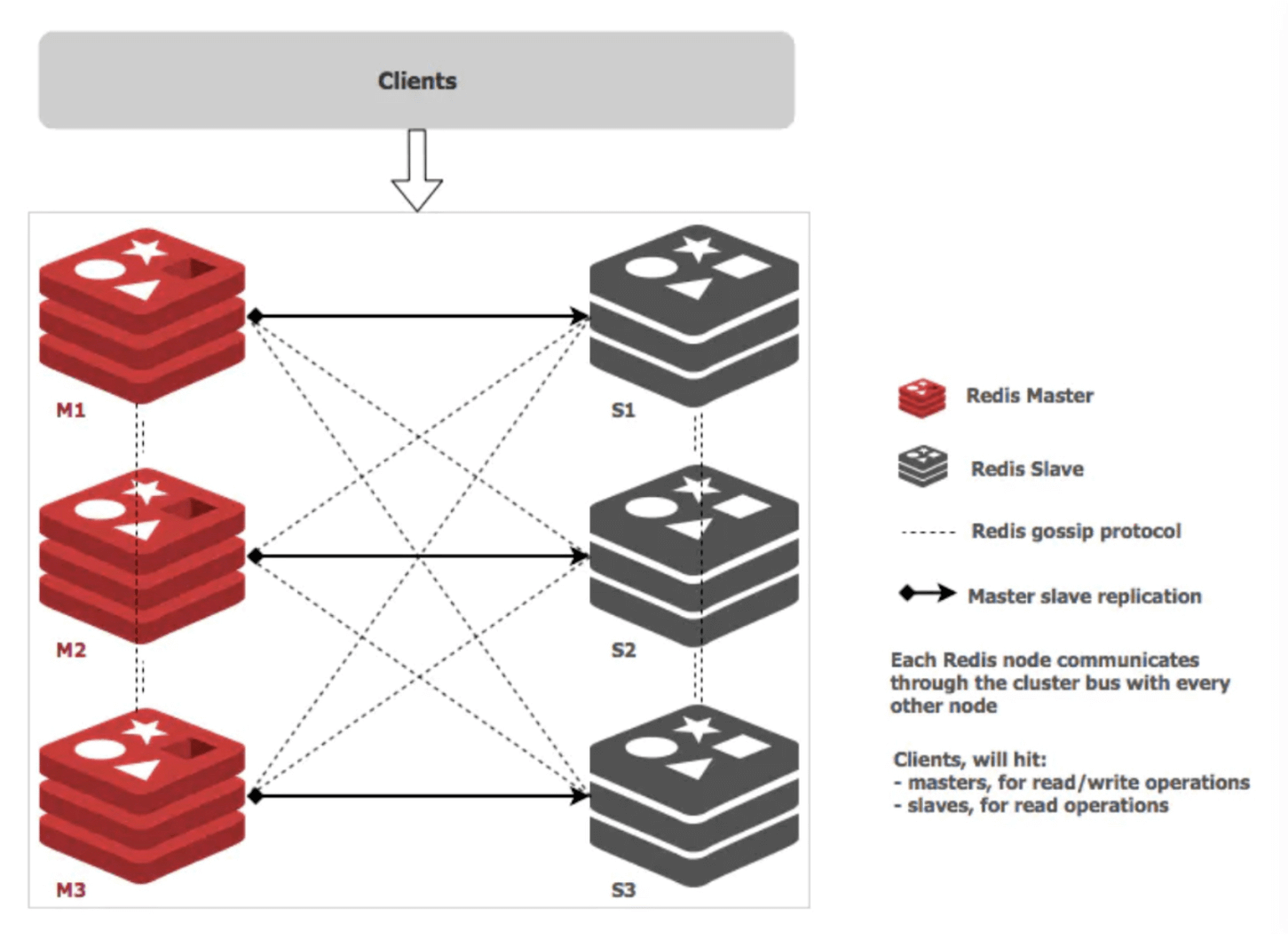
Gossip 通信机制
每个节点维护一份自己视角下整个集群的状态,主要包含:
- 当前集群状态;
- 集群中各节点所负责的 slot 及 migrate 状态;
- 各节点 master-slave 状态;
- 各节点 PFAIL 状态;
节点之间会发送多种消息,最主要的是节点间会通过发送 PING/PONG 互相探活和交换信息。
Q:**为什么 slot 大小为 16384 而不是 65536(CRC16 产生的 Hash 值有 16bit,即 65536 个值)?**
A:主要由于心跳包大小、节点数量、心跳包压缩比三个方面:
节点间交换信息中包含一个 bitmap 用于表示当前节点负责的槽信息,大小为 16384/8/1024 = 2 KB,当 slot 为 65536 时,大小相应变为 8KB
unsigned char myslots[CLUSTER_SLOT/8];
另外也会携带其他节点的信息,比例约为集群总结点数的 1/10,至少为 3 个节点,导致节点越多,心跳包消息头越大,所以作者建议节点数不大于 1000。
bitmap 传输中会进行压缩,bitmap 填充率(slot/N N为节点数)很高的情况下,压缩率变低。
综上,作者的 16384 是一个权衡下的最合适的选择。
请求重定向
每个节点只负责部分 slot,以及一个 slot 存在迁移的情况,所以客户端有可能向错误的节点发起请求,故通过请求重定向来进行发现和修正。有两种重定向:
- MOVED 重定向
一般发生在已经迁移完成后,请求的 key 对应的 slot 不在该节点,节点会回复 MOVED错误,需要客户端再次重试,且更新 slots 缓存。例如:
GET x -MOVED 3999 127.0.0.1:6381 - ASK 重定向
一般发生在数据迁移中,被请求节点判断 key 对应的 slot 目前状态属于 MIGRATING 状态(节点正在迁移 slot 到另一个节点)。客户端收到 ASK 错误后,会发送 ASKING 命令请求重定向对应的目标节点(即 IMPORTING 节点),此时客户端不会更新 slots 缓存。
为什么 Redis 需要两种重定向呢,只实现 MOVED 不行吗?
只存在 MOVED 意味着每次重定向都会更新客户端缓存,但由于 Redis 迁移 Key 是以 Slot 为单位的,一个 Slot 存在一批 Key。
所以,在发生 Slot 迁移的情况下,虽然本次请求的 Key 迁移到了目标节点中,但是可能仍有部分 Key 还未迁移到目标节点中,仍然在原节点中,所以不能直接更新客户端缓存。因此需要两种重定向标志。
另外,若重定向超过 5 次则抛出异常:
Too many cluster redirection
Failover 过程
Failover 表现在一个 master 分片故障后,slave 接管 master 的过程。
过程可以分为两个阶段:
- 故障检测
- 主观故障检测:每个节点会对 PING 超时(超过 cluster_node_timeout)的节点标记疑似下线状态(Probable Fail,PFAIL)
- 客观故障检测:每个节点统计集群中所有主节点发送的 PFAIL 节点消息,若本节点视角下集群过半主节点将某节点标记 PFAIL,且本节点对某节点标记为了 PFAIL,那么标记其为客观下线(FAIL)。如果当前节点是主节点,还会对节点 FAIL 的消息进行集群广播。
- 选举及故障转移
- 从节点发起选举:当 FAIL 节点的从节点感知到自己的 master 状态时,会广播投票消息来拉票,请求所有具备投票权的节点给自己投票(这些节点必须是 master 且必须对某些 slot 负责)。
- 拉票过程:拉票并不是立即执行的,由于 master 可能有多个 slave,所以 slave 感知到 master FAIL 时会进行优先级排序,以自己的主从复制偏移量作为排序依据,排序越高说明和 master 数据越接近,则会先发起拉票(先拉票则成为 master 的可能性越大),排序越低的则发起拉票的时间会相应延迟一段时间。
- 主节点投票:主节点会给从节点响应 ACK 来进行投票,对应的从节点收到后会进行票数统计。
- 计票并完成主从切换:在所有发起投票的从节点中,得票超过半数主节点的从节点有资格成为新 master,并接管原 master,并向集群所有节点广播这个大好的消息。(若没有从节点得票过半,那就会重新进行下轮选举,直到选出新节点为止)。
详细源码我会单独写一篇总结。
- 缺点
- 批量操作比较麻烦,相比于 codis 这类 proxy 架构可以将 mget 等批量操作按照key分组后发送给对应的实例,最后汇总返回给客户端;
Redis cluster只能通过hashtag或客户端封装分组逻辑来完成批量操作,不支持跨节点操作
否则会报错:No way to dispatch this command to Redis Cluster because keys have different slots
- 批量操作比较麻烦,相比于 codis 这类 proxy 架构可以将 mget 等批量操作按照key分组后发送给对应的实例,最后汇总返回给客户端;
Codis vs. Twemproxy vs. Redis Cluster
| Codis | Twemproxy | Redis Cluster | |
|---|---|---|---|
| resharding without restarting cluster | Yes | No | Yes |
| pipeline | Yes | Yes | No |
| hash tags for multi-key operations | Yes | Yes | Yes |
| multi-key operations while resharding | Yes | – | No(https://redis.io/docs/reference/cluster-spec/#multi-keys-operations) |
| Redis clients supporting | Any clients | Any clients | Clients have to support cluster protocol |
“Resharding” means migrating the data in one slot from one redis server to another, usually happens while increasing/decreasing the number of redis servers.
Redis Enterprise
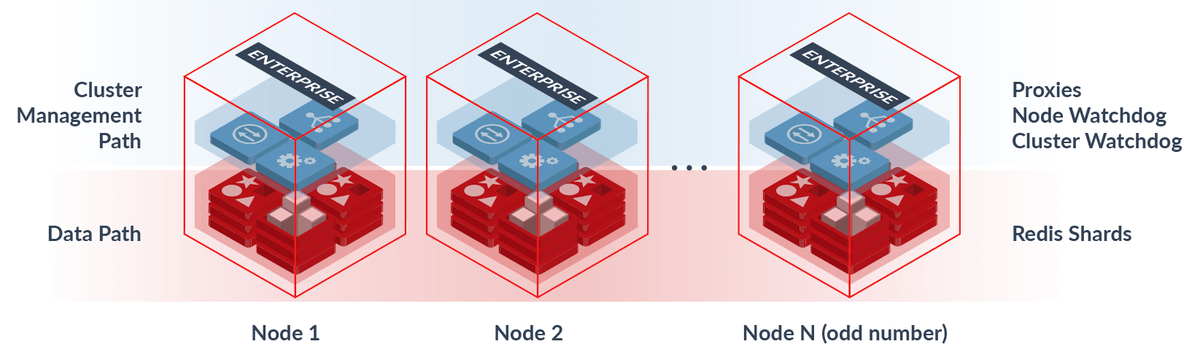
尽管 Redis 开源版本已经提供高可用、高性能、易部署的集群架构方案,但是对于大规模企业来说,直接企业级应用还不够。大规模的企业通常需要更多能力,例如安全性、多租户、监控、节点管理等等。
各大公司都会在 Redis 各种集群架构方案的基础上改造搭建自己的企业级 Redis 应用,Redis 官方也推出 Redis Enterprise 提供更高的可用性(99.999%)、秒级 Failover、无限线性拓展、双活架构等等特性。
参考