
文章目录
概述
什么是 I/O ?
I/O 是指 Input/Output,即输入和输出。以内存为中心:
- Input 指从外部读入数据到内存,例如,把文件从磁盘读取到内存,从网络读取数据到内存等等。
- Output 指把数据从内存输出到外部,例如,把数据从内存写入到文件,把数据从内存输出到网络等等。
为什么要把数据读到内存才能处理这些数据?因为代码是在内存中运行的,数据也必须读到内存,最终的表示方式无非是byte数组,字符串等,都必须存放在内存里。
我们讨论的网络 I/O 就是对网卡的读写,网络 I/O 在 Web 应用中十分重要,网络框架的设计离不开 I/O 模型,模型的优劣直接决定了系统的吞吐量、可扩展性、安全性等。
本文主要总结5种 I/O 模型及应对高并发的 I/O 事件处理模型和应用。
网络 IO 过程(TCP)
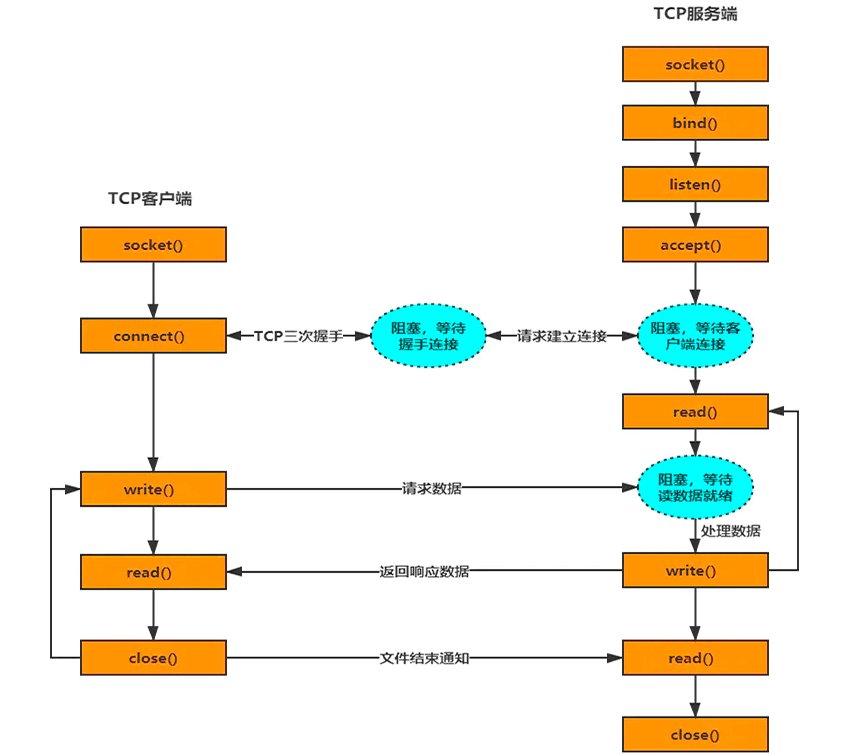
- accept:从全连接队列中取一个连接;
- connect:请求进行三次握手,建立连接;
- read:把数据从接收内核缓冲区复制到进程缓冲区;
- write:把数据从进程缓冲区复制到内核的发送缓冲区。
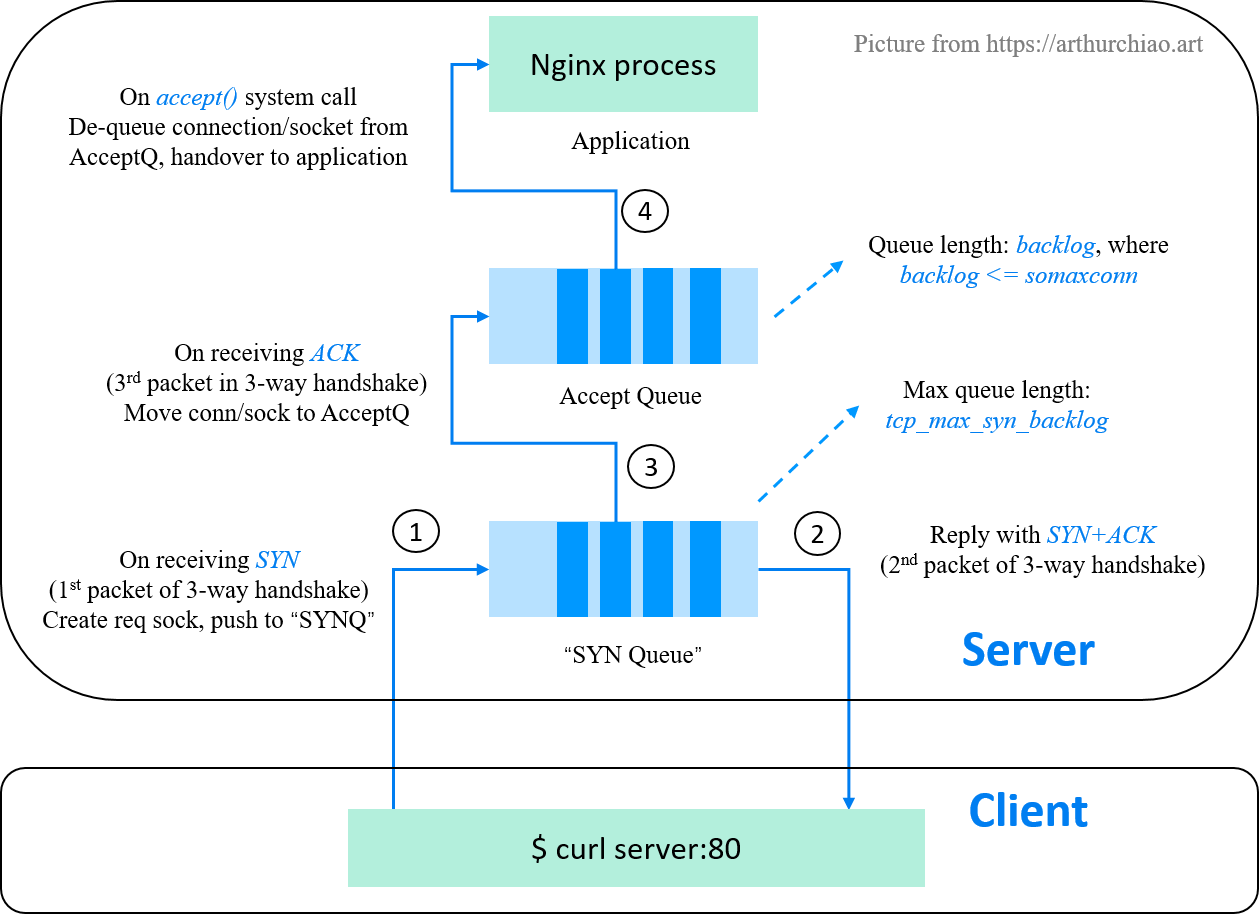
关于 accept() 函数的作用:
Linux 实现中 TCP 建立连接时,依赖两个队列,一个 Syn 队列(半连接队列,Hash 表结构),一个 Accept 队列(全连接队列,链表结构),这两个队列是在执行 listen() 时创建的)。
syn/accept 队列
TCP 三次握手要经过:
- Client -> Server: SYN
- Server -> Client: SYN+ACK
- Client -> Server: ACK
在第 1 步 Server 收到 SYN 后,会把消息放到 Syn Queue 中,并回复 SYN+ACK 给 client,当第 3 步 Server 收到 ACK 后,如果这时 Accept Queue 未满,则从 Syn Queue 中取出暂存的信息放入 Accept Queue 中。若满了,则按
net.ipv4.tcp_abort_on_overflow设置的值执行:
net.ipv4.tcp_abort_on_overflow = 0表示如果三次握手第三步的时候 Accept Queue 满了,则 Server 丢弃 Client 发过来的 ACK 。net.ipv4.tcp_abort_on_overflow = 1表示第三步的时候如果全连接队列满了,Server 发送一个 RST 包给 Client ,表示拒绝这个握手过程和这个连接。那么回到 accept() 的作用,实际上建立连接的过程中不需要
accept()参与, 执行 accept() 只是为了从全连接队列里取出一条连接。
常见的 IO 模型
BIO(同步阻塞)
ServerSocket serverSocket = new ServerSocket();
serverSocket.bind(8888);
while (1) {
// 1. 等待连接,同步阻塞
Socket socket = serverSocket.accept();
threadPool.execute(() -> {
// 2. 读取数据
String someThing = socket.read()
if(someThing!=null){
//3. 处理数据
bizLogic();
// 4. 写数据
socket.write();
}
})
}
- 第一步:等待连接(accept)同步阻塞,等待可用连接(例如完成 tcp 三次握手的连接)。
- 二、三步:数据传输又可以分成两个阶段,以 read() 为例:
- 等待数据就绪:CPU 向网卡发出 I/O 请求,网卡在接收到数据之后,由网卡的 DMA 把的数据写到操作系统的内核缓冲区,完成后通知 CPU。
- 将数据从内核拷贝到用户空间:CPU 将数据拷贝到用户空间,消耗 CPU 但性能非常高。
由于是同步阻塞的,所以 read() 会一直阻塞直到数据从内核拷贝到用户空间才返回;write() 也类似,需要等待所有数据都写到发送缓冲区才返回(发送缓冲区一边往外发数据,一边应用往里写,不够写就一部分一部分写等待数据发送后有空出来的空间,直到全部写入)。
BIO 在活动连接数不是特别高(小于单机1000)的情况下是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单。但是缺点也很明显:
- 依赖线程,当活动连接数以万计时,需要创建大量线程,此时线程就要占用大量内存;
- 线程上下切换影响 CPU load、CPU sys使用率;
- 对于长连接,线程的资源一直不会释放,可能造成之后的连接无法处理。
所以出现了各种新 I/O 模型来应对上万甚至上百万连接。
NIO(同步非阻塞)
非阻塞主要体现在用户发起 IO 请求后,不需要等待,无论成功失败,可以直接获取到对应的结果(内核数据是否就绪),当结果是 error时,就再次发送 IO 请求。例如:
- 非阻塞读:
- 若 Socket 接收缓冲区中无数据,系统调用立马返回,并带有一个 EWOULDBLOCK 或 EAGAIN 错误,这个阶段用户线程不会阻塞,也不会让出CPU,而是会继续轮训直到 Socket 接收缓冲区中有数据为止;
- 若 Socket 接收缓冲区中有数据,用户线程在内核态会将内核空间中的数据拷贝到用户空间,注意这个数据拷贝阶段,应用程序是阻塞的,当数据拷贝完成,系统调用返回。
- 非阻塞写:
- 不同于阻塞写的苦等数据写完,非阻塞写比较佛系,当发送缓冲区中没有足够的空间容纳全部发送数据时,非阻塞写的特点是能写多少写多少,写不下了,就立即返回。并将写入到发送缓冲区的字节数返回给应用程序,方便用户线程不断的轮询尝试将剩下的数据写入发送缓冲区中。
NIO 最大的问题就是需要不断的发起系统调用去轮询各个 Socket 中的接收缓冲区是否有数据到来,频繁的系统调用随之带来了大量的上下文切换开销。随着并发量的提升,这样会导致非常严重的性能问题, 造成 CPU 的浪费。
IO Multiplexing(IO 多路复用)
// Java NIO 实现多路复用
void serverInit() {
// 1. 创建 Selector 和 Channel
try (Selector selector = Selector.open(); ServerSocketChannel serverSocket = ServerSocketChannel.open();) {
serverSocket.bind(new InetSocketAddress(InetAddress.getLocalHost(), 8888));
serverSocket.configureBlocking(false);
// 2. 注册到 Selector,并声明关注的事件类型(服务端,关注连接事件)
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 3. 阻塞,等待就绪的 Channel
selector.select();
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> iter = selectedKeys.iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
if (!key.isValid()) {
continue;
}
if (key.isAcceptable()) {
// 4.获取连接,并注册读事件监听
accept(serverSocket, selector);
} else if (key.isReadable()) {
read(key);
} else if (key.isWritable()) {
write(key);
}
iter.remove();
}
}
} catch (IOException e) {
..
}
}
void accept(ServerSocketChannel serverSocket, Selector selector) {
SocketChannel sc = serverSocket.accept();
sc.configureBlocking(false);
sc.register(selector, SelectionKey.OP_READ);
}
void read(SelectionKey key) {
SocketChannel sc = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
sc.read(buffer);
}
void write() {
...
}
上述代码的 select() 方法在 Linux 操作系统内核下最终会调用到 EPollSelectorImpl#doSelect(...) (参考 openJdk),最终由操作系统提供通知机制,当内核数据就绪时才返回。
Linux 通过 select、poll、epoll 这三个函数实现这样的机制。
- select(1983 Unix 4.2 BSD):当被监听的 fd(文件描述符)就绪后会返回,但是我们无法知道具体是哪些 fd 就绪了,只能遍历所有的 fd。通常来说某一时刻,就绪的 fd 并不会很多,但是使用 select 必须要遍历所有的 fd,这就造成了一定程度上的性能损失。select 最多可监听的 fd 是有限制的,32位操作系统默认 1024 个,64 位默认 2048;
- poll(1997 Linux 2.1.23):和 select 一样,使用 poll 时也无法知道具体哪些 fd 就绪了,还是需要遍历。poll 最大的改进就是没有了监听数量的限制,但是监听了过多的 fd 会导致性能不佳;
- epoll(2002 Linux 2.5.44):通常在 Linux 系统中使用 IO 多路复用,都是在使用 epoll 函数。epoll 是 select 和 poll 的增强,可以通知我们哪些 fd 已经就绪了,并且没有监听数量的限制。所以使用 epoll 的性能要远远优于 select 和 poll,目前 linux 2.6 以上都使用 epoll。
epoll 不同于依赖轮询的 select 和 poll,它包括以下系统调用
// 创建一个池子监控和管理 fd int epoll_create(int size) // 负责管理这个池子里的 fd 事件的增、删、改 (红黑树) int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); // 就是负责打盹的,让出 CPU 调度,但是只要有“事”,立马会从这里唤醒 epollwait()通过 epoll_ctl 将某个 fd 可读/可写等等事件添加到红黑树,这些事件都会与设备 (网卡)驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个回调函数。
回调函数的任务是把事件就绪的 fd 对应的结构体放到一个特定的队列(就绪队列,ready list),然后把 epoll 从 epollwait 中唤醒。
因此 epoll 被称为事件驱动。
另外,上面的 read() 实现,我们创建了一个 1024 字节的缓冲区,用于数据的读取。如果连接中的数据,大于 1024 字节怎么办?这涉及两种事件的通知机制:
- 水平触发(level-triggered) 称作 LT 模式。只要缓冲区有数据,事件就会一直发生
- 边缘触发(edge-triggered) 称作 ET 模式。缓冲区有数据,仅会触发一次。事件想要再次触发,必须先将 fd 中的数据读完才行
在Netty中实现的EpollSocketChannel默认的就是边缘触发模式。JDK的NIO默认是水平触发模式。LT 模式频繁环唤醒线程,效率相比较ET模式低。
IO 多路复用即使用一个线程中就可以监听多个 (Linux 中万物皆是文件描述符,网络编程中即是 Socket),一旦某个 FD 就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
多路是指网络连接,复用指的是同一个线程。
Signal Driven IO(信号驱动 IO)
用户线程发起一个 IO 请求操作,会给对应的 socke t注册一个信号函数,之后立即返回,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号后,便在信号函数(callback)中调用 IO 读写操作来进行实际的IO请求操作。
一般用于UDP中,对TCP套接字几乎没用,原因是该信号产生得过于频繁,并且该信号的出现并没有告诉我们发生了什么请求。
Asynchronous IO (异步 IO)
之前的几种 IO 模型实际上都属于同步 IO,只有最后一种是真正的异步 IO,因为无论是多路复用IO 还是信号驱动模型,IO操作的第 2 个阶段都会引起用户线程阻塞,也就是内核进行数据拷贝的过程都会让用户线程阻塞。
异步 IO 的主要机制就是在完成 IO ,即数据完成从内核空间复制到用户空间时,才会通知调用方。
与上述的信号 IO 模型区分在于异步是通知我们何时 IO 操作完成,而信号 IO 是通知我们何时可以启动一个 IO 操作。
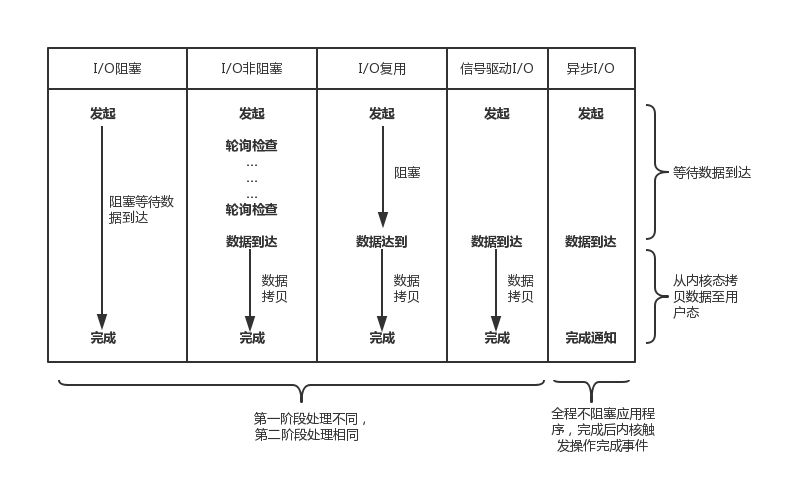
对比
前面介绍的5中I/O中,I/O 阻塞、I/O非阻塞、I/O复用、SIGIO 都会在不同程度上阻塞应用程序,而只有异步I/O模型在整个操作期间都不会阻塞应用程序。
概念区分
同步 vs. 异步
- 同步:调用 function 的结果必须等待其返回。
- 异步:调用 function 后立即返回,结果通过回调或者事件等主动通知调用方。
二者主要描述的是通信方式的区别。
阻塞 vs. 非阻塞
- 阻塞:调用结果返回之前,当前调用方会被挂起。调用线程只有在得到结果之后才会返回。
- 非阻塞:不能立刻得到结果之前,该调用不会阻塞调用方,而是直接返回有、无、或者有部分结果等。
二者主要描述的是通信过程中调用方状态的区别。
I/O 模型是为了解决内存和外部设备速度差异的问题。我们平时说的阻塞或非阻塞是指应用程序在发起 I/O 操作时,是立即返回还是等待。而同步和异步,是指应用程序在与内核通信时,数据从内核空间到应用空间的拷贝,是由内核主动发起还是由应用程序来触发。
事件处理模型
网络设计模式中,如何处理各种 I/O 事件是其非常重要的一部分,大名鼎鼎的 Java 并发包作者 Doug Lea,在 Scalable I/O in Java 一文中阐述了服务端开发中 I/O 模型的演进过程。Netty 中三种 Reactor 线程模型也来源于这篇经典文章。上面将 I/O 分为同步 I/O 和 异步I/O,可以使用同步 I/O 实现 Reactor 模型,使用异步 I/O 实现 Proactor 模型。
Java NIO SelectionKey 中定义了 4 种事件:
OP_ACCEPT:接收连接事件,表示服务端与(至少一个)客户端已完成连接(如三次握手),此时服务端可以获取连接了;OP_CONNECT:连接就绪事件,客户端调用 connect() 尝试进行连接服务端,该操作就绪;OP_READ—— 读就绪事件,当内核的读缓冲区中有数据可读时,该操作就绪;OP_WRITE—— 写就绪事件,内核的写缓冲区中有空闲的空间时(大部分时候都有),该操作就绪。
Reactor
也称为 Dispatcher 模式,核心原理是利用 NIO 对 IO 线程进行不同的分工:
- 使用前边我们提到的IO多路复用模型比如
select,poll,epoll,kqueue,进行IO事件的注册和监听; - 将监听到就绪的 IO 事件分发 dispatch 到各个具体的处理 Handler 中进行相应的IO事件处理。
通过 IO 多路复用技术就可以不断的监听 IO 事件,不断的分发 dispatch,就像一个反应堆一样,看起来像不断的产生 IO 事件,因此称这种模式为 Reactor 模型。
注:一般业务处理包含三步:decode、compute、encode
单线程 Reactor
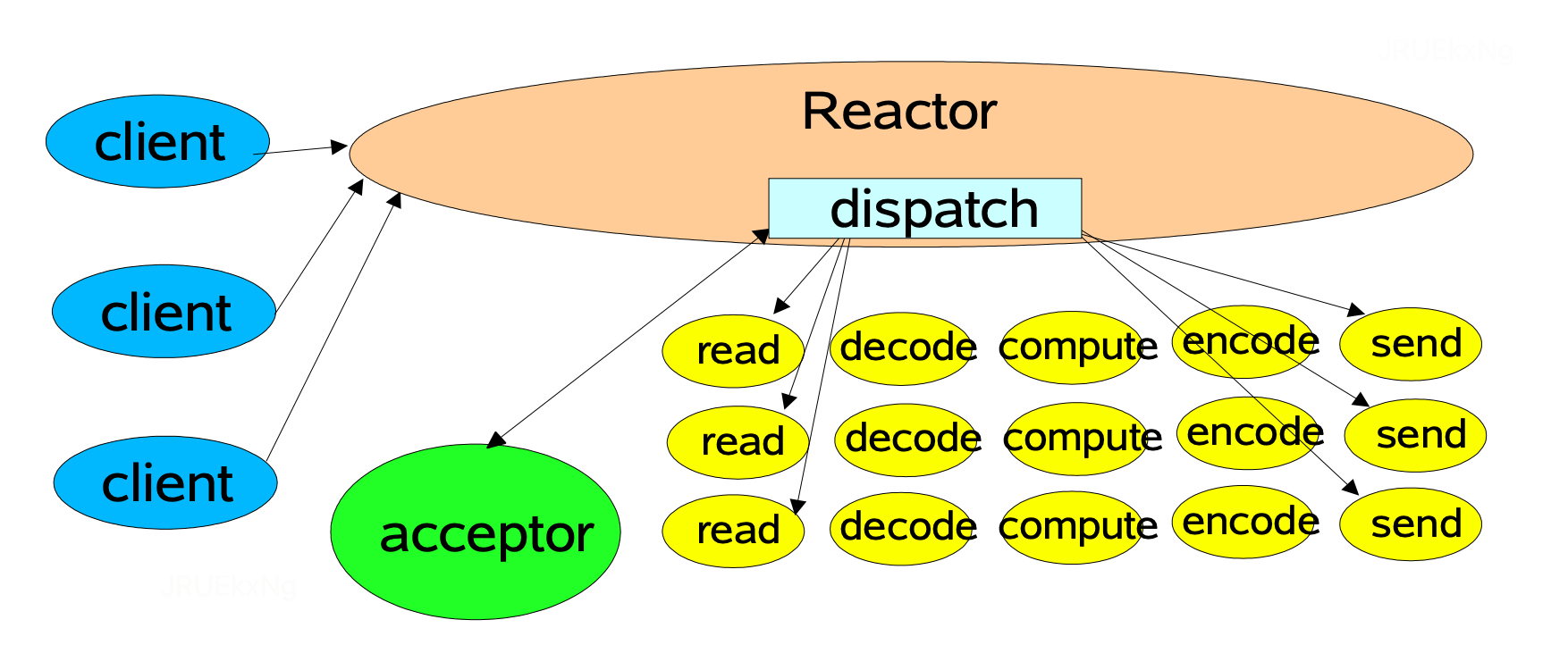
这个模型诠释了 Reactor 模式的组成部分:
- Reactor: 负责分发 I/O 事件,如果是请求建立连接,则由 Acceptor 通过
accept()处理,如果不是连接建立请求,则 Reactor 会将事件分发给具体的处理逻辑来执行(数据读取、编解码、业务逻辑等); - Acceptor:获取连接,注册读事件监听。
单线程 Reactor 线程模型简单,没有引入多线程,自然也就没有多线程并发和竞争的问题。
但其缺点也非常明显,那就是性能瓶颈问题,一个线程只能跑在一个 CPU 上,能处理的连接数是有限的,无法完全发挥多核 CPU 的优势。一旦某个业务逻辑耗时较长,这唯一的线程就会卡在上面,无法处理其他连接的请求,程序进入假死的状态,可用性也就降低了。正是由于这种限制,一般只会在客户端使用这种线程模型。
多线程 Reactor
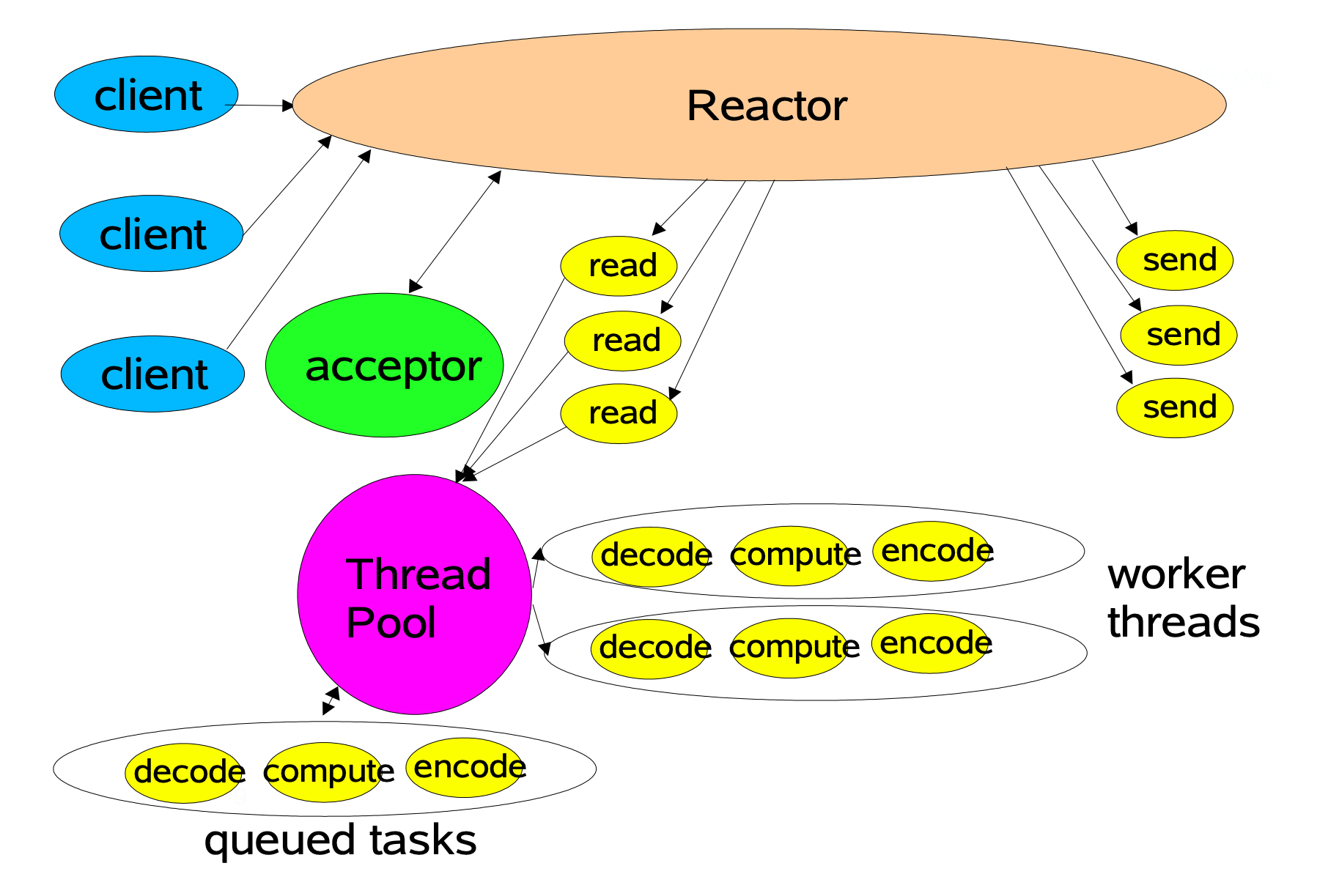
多线程 Reactor 通过引入线程池处理读写请求来解决单线程 Reactor 的性能问题,除开这点其他流程与单线程模型基本一致。这个模型存在的问题是,只有一个线程来处理 Reactor 监听到的所有 I/O 事件,包括连接建立事件以及读写事件,当连接数不断增大的时候,这个唯一的 Reactor 线程也会遇到瓶颈。
主从多线程 Reactor
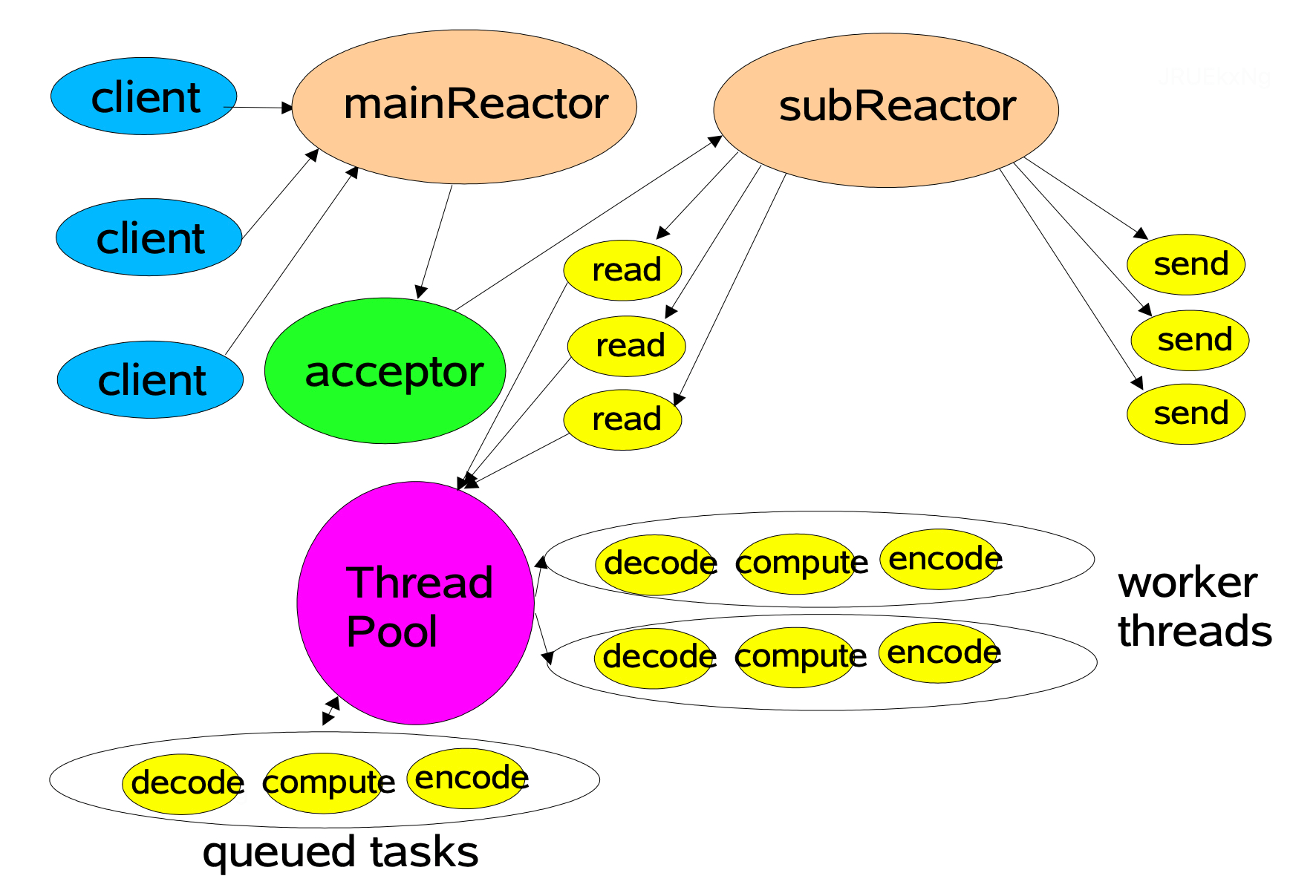
为了解决单 Reactor 多线程模型中的问题,可以引入多个 Reactor。MainReactor 线程负责通过 Acceptor 对象处理其监听到的连接建立事件,当 Acceptor 完成网络连接的建立之后,MainReactor 会将建立好的连接分配给 SubReactor 进行后续读事件监听。当有新的读事件(OP_READ)发生时,SubReactor ,然后分发给 Worker 线程池中的线程进行处理并返回结果
主从 Reactor 多线程的设计模式解决了单一 Reactor 的瓶颈。主从 Reactor 职责明确,主 Reactor 只负责监听连接建立事件,SubReactor只负责监听读写事件。整个主从 Reactor 多线程架构充分利用了多核 CPU 的优势,可以支持扩展,而且与具体的业务逻辑充分解耦,复用性高。但不足的地方是,在交互上略显复杂,需要一定的编程门槛。
Proactor
Proactor 模型采用异步 IO 实现(AIO),事件处理器(或者代由事件分发器发起)直接发起一个异步读写操作(相当于请求),而实际的工作是由操作系统来完成的,事件处理器不再关心操作就绪事件而是关注完成事件,由内核完成 IO 操作后,通知事件分离器,最后呼唤事件处理器调用自定义 handler 进行业务处理。目前 Linux 操作系统内核尚未实现 AIO (Windows 实现了 AIO)。
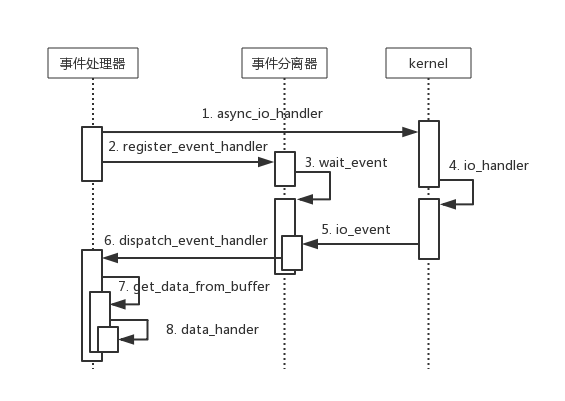
应用
- Netty: 单线程、多线程、主从 Reactor 模型都有实现(Netty 中的 EventLoop 就是 Reactor);
- Memcached: 多线程 Reactor 模型;
- Nginx: 多进程 Reactor 模型;
- Redis: v6.0 前单线程 Reactor 模型,v6.0 后采用主从 Reactor 模型;
- 和经典主从 Reactor 不一样的地方在于,decode 和 encode 在从 Reactor 线程组执行,更大的区别是 Redis 命令的运行也是由主 Reactor 线程执行。
- Tomcat(NIO):主从 Reactor 模型(Acceptor 主 → Poller 从→ BizThread)。
- 不同于 Netty 的主从 Reactor,Tomcat 监听到读事件时会交给业务线程读数据并处理业务逻辑,之后才继续读下一个请求的数据;不像 Netty I/O 读写由 I/O 线程负责,读完才交给业务线程处理。由于 Tomcat 针对的是 Http 协议,不像 RPC 常用的复用连接(即发请求可以不用等当前请求返回就可以继续发),Tomcat 这样处理也合理。
参考:
Scalable IO in Java – Doug Lea
Linux I/O Principles and Zero-copy Technology