
文章目录
概述
HBase 是 Hadoop Database 的简称,是建立在 HDFS 之上的面向列的分布式、扩拓展、支持实时对海量数据进行随机读/写,是一种非关系型数据库(NoSQL)。相比于传统数据库,它不支持 SQL 的跨行事务,可以存储结构化和半结构化的数据,本质上是Key-Value数据库。
对比 HDFS
本质上 HBase 是个存储系统,那既然有 HDFS 为什么需要 HBase 呢?
| HDFS | HBase |
|---|---|
| HDFS is a java based file distribution system | Hbase is hadoop database that runs on top of HDFS |
| HDFS is highly fault-tolerant and cost-effective | HBase is partially tolerant and highly consistent |
| HDFS Provides only sequential read/write operation | Random access is possible due to hash table |
| HDFS is based on write once read many times | HBase supports random read and writeoperation into filesystem |
| HDFS has a rigid architecture | HBase support dynamic changes |
| HDFS is prefereable for offline batch processing | HBase is preferable for real time processing |
| HDFS provides high latency for access operations. | HBase provides low latency access to small amount of data |
总的来说就是二者的侧重点或者定位不同,HDFS 定位是存储大规模数据的文件系统,而 HBase 是支持频繁随机读写的大型数据库系统(实现上本质就是 HBase 为 HDFS 的数据建索引来实现随机读写)。
架构
- Client
提供 API 并具备 Cache 能力。
-
Zookeeper
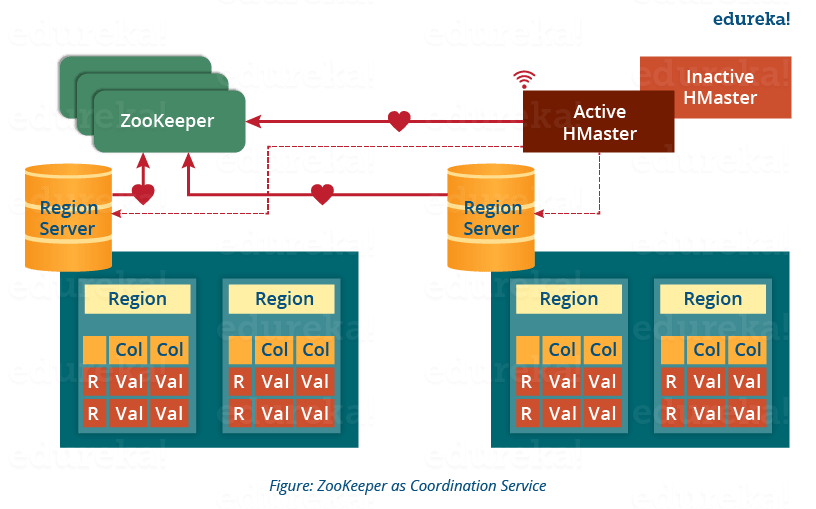
作为分布式协调服务,通过心跳检测 HMaster 、RegionServer 状态,提供 HA 保障,管理HBase 集群中的所有节点,包括节点的加入和离开,以及节点的状态变化等。
另外还保存 HBase 元数据(meta 表)信息,但并不存放直接存放 meta 数据,而是 meta 表的索引。meta 表由 regionserver 里的 root region 存储,meta 表相当于其他表的索引,而zookeeper 放的是 meta 表的索引,相当于索引的索引。
-
HMaster
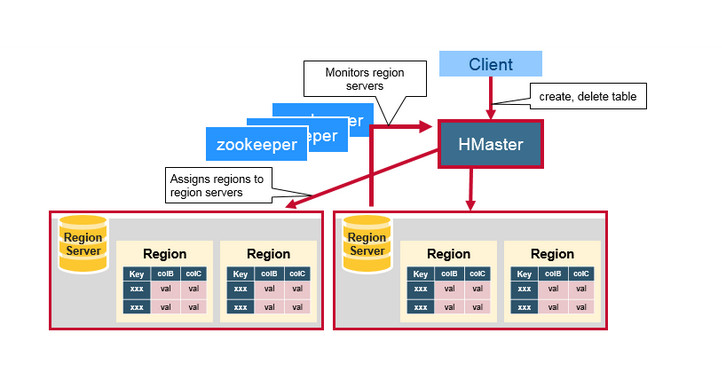
主要作用是管理集群,用于协调多个 Region Server,侦测各个 Region Server 的状态,并平衡 Region Server 之间的负载;还负责分配 Region 给 Region Server。
容错:主从架构,Zookeeper 检测心跳、帮助选主,避免单点。
-
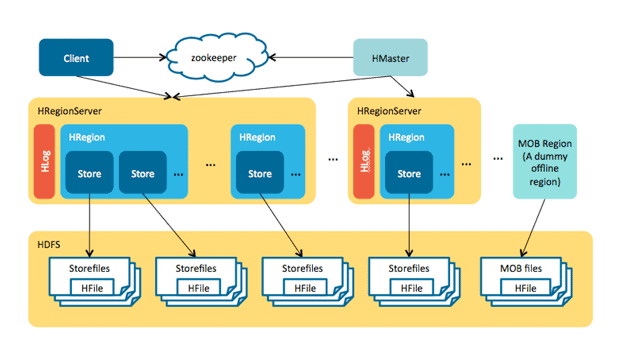
HRegionServer
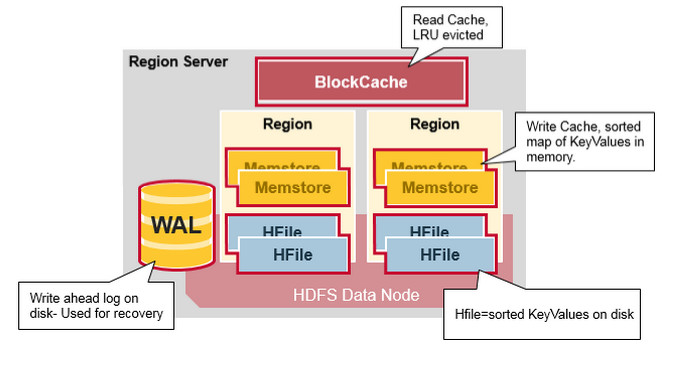
负责数据的存储。组件包括:
- WAL(HLOG): 写入数据先保存 LOG,用于故障恢复;
- Block Cache: 缓存(LRU);
- MemStore: 写缓存,一个 Rigion 中的每个列族保存在一个 MemStore 中,数据有序保存;
- HFile: 负责数据持久化,当 MemStore 积累足够多数据,就会新建一个 HFile 保存,顺序写在 HDFS 上。
容错:Zookeeper 将故障节点通知给 HMaster,HMaster 会重新分配一个 Region Server 负责原节点的 Regions,并且重放 WAL 文件恢复还未持久化的数据。
数据模型
表逻辑结构

HBase 中的值由 5 个维度组成:
(Table, RowKey, Family, Column, Timestamp) => Value (Cell)
- Table
表是在schema声明的时候定义的。
-
RowKey
行键相当于这一行的标识符,是不可分割的字节数组。行是按字典排序由低到高存储在表中的。用一个空的数组来标识表空间的起始或者结尾。
-
Column Family
Column Family 是一些列的集合。一个列族所有列成员是有着相同的前缀。比如,列courses:history 和 courses:math 都是列族 courses 的成员。冒号(:)是列族的分隔符,用来区分前缀和列名。
在物理上,一个的列族成员在文件系统上都是存储在一起。因为存储优化都是针对列族级别的,这就意味着,一个colimn family的所有成员的是用相同的方式访问的。
-
Column
在HBase中用列修饰符(Column Qualifier)来标识每个列。上图中的 Name, Phone 等都是 Qualifier,可以由任意字节数组组成。列族必须在表建立的时候声明。但 Column 就不需要了,随时可以新建。而且每一行中,列的组成都是灵活的,行与行之间的列不需要相同。
-
Timestamp(Version)
版本(默认是时间戳)以长整型表示,用于区分不同的 Cell。由于 HBase 是追加写,所以修改内容的时候实际上是新增了一条数据,同时版本号+1 而已。在HBase中,版本是按倒序排列的,因此当读取这个文件的时候,最先找到的是最近的版本。
-
Cell
A {row, column, version} 元组就是一个 HBase 中的一个 Cell。Cell 的内容是不可分割的字节数组。
可以用 Java 语言表达这样的结构关系(只是示意):
**SortedMap<RowKey, List<SortedMap<Column, List<Value, Timestamp>>>>
第一个 SortedMap 表示 table,通过 RowKey 定位到一组 CF,CF 包含另外一个 SortedMap,通过** Qualifier 定位到具体的 Cells(含 Value 和 Ts)。
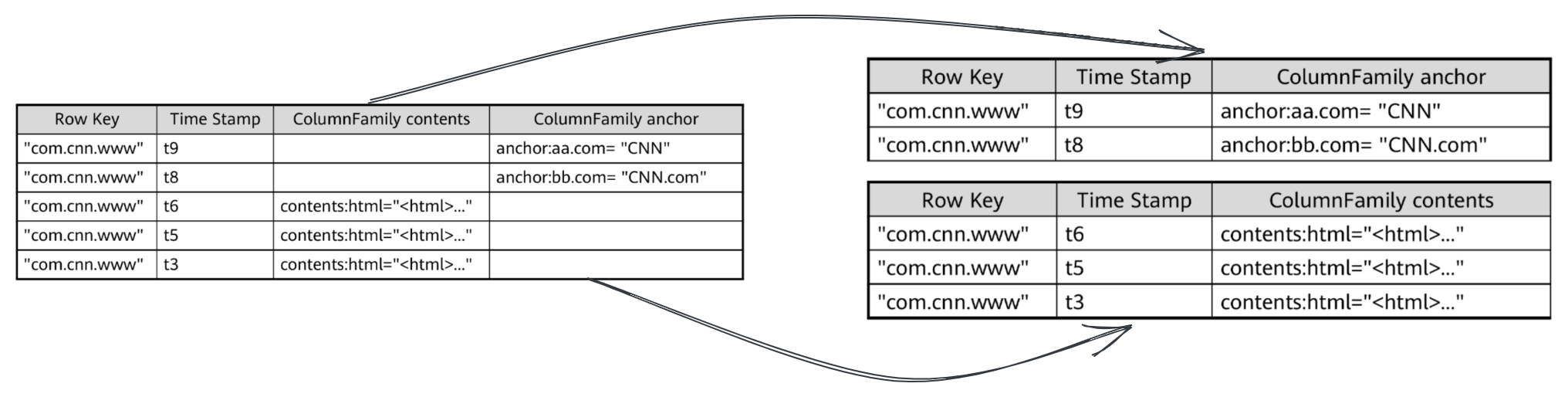
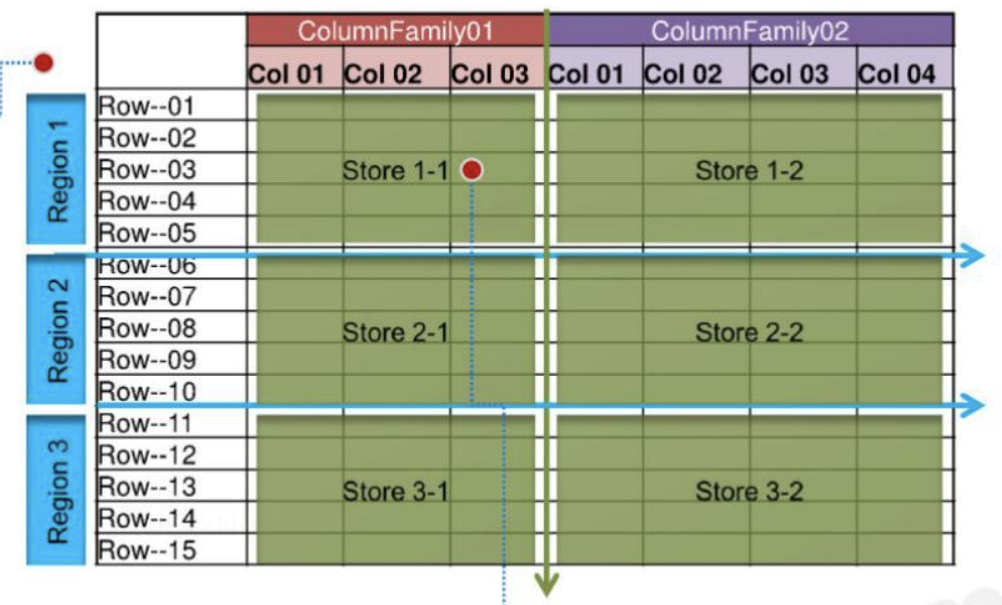
表物理存储结构
物理上,表是按列族存储的,并且空的 Cell 在物理上是不存储的。
底层数据结构
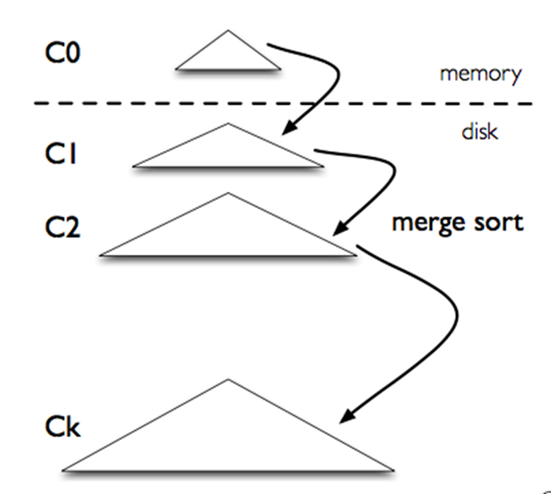
不同于 MySQL 等 RDBMS 采用 B 树或 B+ 树等数据结构作为底层存储架构,HBase 则采用 LMST (Log-Structure Merge-Tree)的方式组织磁盘数据,目的是提高写性能。
LSM 树并不像 B+树、红黑树一样是一颗严格的树状数据结构,它其实是一种存储结构。通常包含两部分,一部分是在内存中的树,包含最近更新内容的,另一部分是在磁盘中,包含早先的数据。随着数据增加内存中的数据会持久化到磁盘,形成很多小文件,而这些文件会进行归并(称为滚动合并)。
通过 B+ 树写入时需要先通过 IO 加载树节点查到写入数据所属的磁盘页,面对大量写入时,磁盘随机写概率较大,另外还可能产生页分裂,这些都会影响写入吞吐量;
而 LMS 采用追加写的方式,使得写入不依赖于查询,并且数据写入不需要访问磁盘,在内存即可完成,因此速度远快于 B+树。
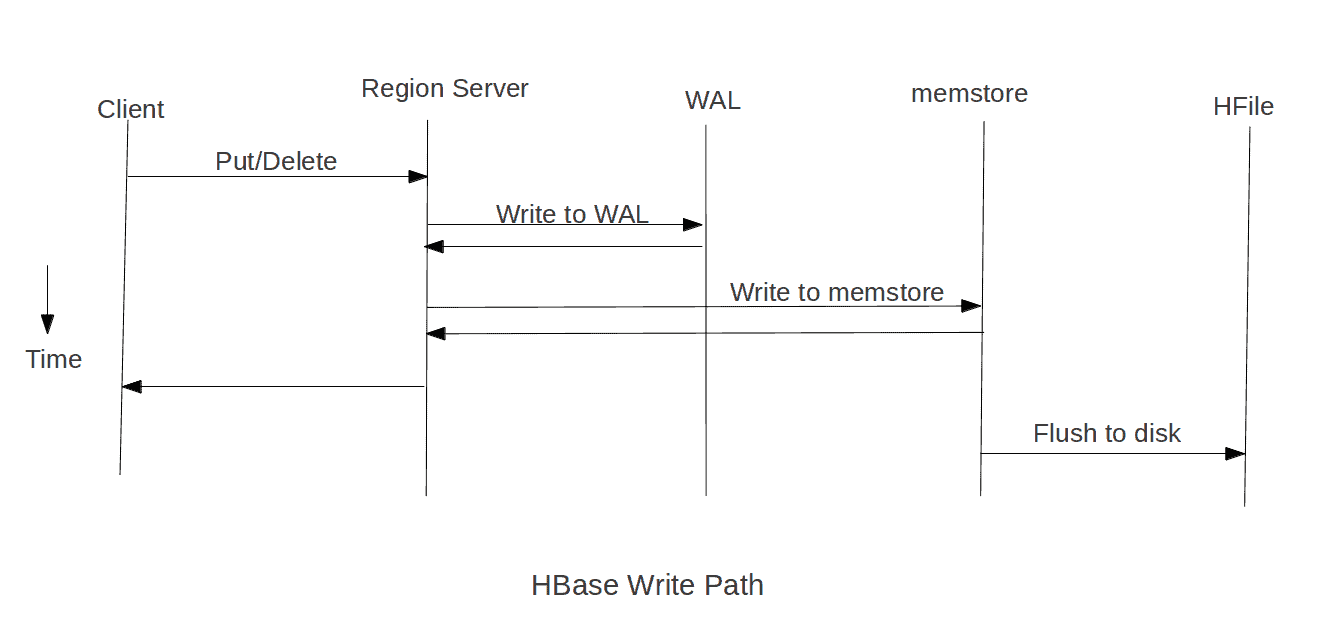
HBase 写入数据会首先利用 MemStore (称为写缓存)进行存储,保证其按照 RowKey 有序。然后等待时机 flush 到 HFile 进行持久化(HFile 中的数据自然也是有序的)。而写入一般是先顺序写入 WAL 再写入内存。后台线程会自动把小 HFile 归并为 大HFile,减少读范围,提升读性能。

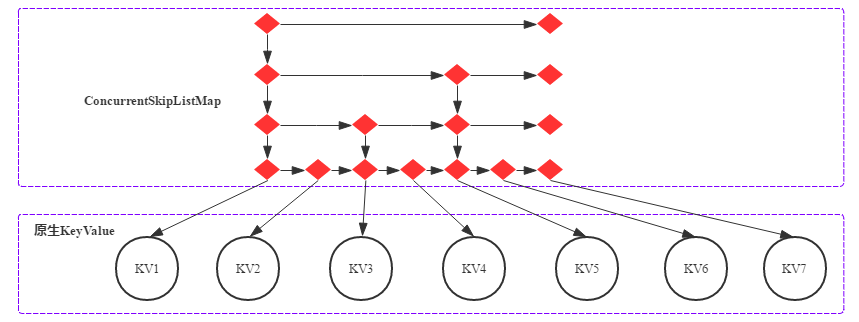
****MemStore****
MemStore 底层实现是 SkipList,跳表可以实现高效的查询\插入\删除操作,这些操作的期望复杂度都是O(logN)。另外,因为跳表本质上是由链表构成,所以理解和实现都更加简单。这是很多KV数据库(Redis、LevelDB等)使用跳表实现有序数据集合的两个主要原因。HBase 跳表优化可以参考:HBase内存管理之MemStore进化论
LMS 树
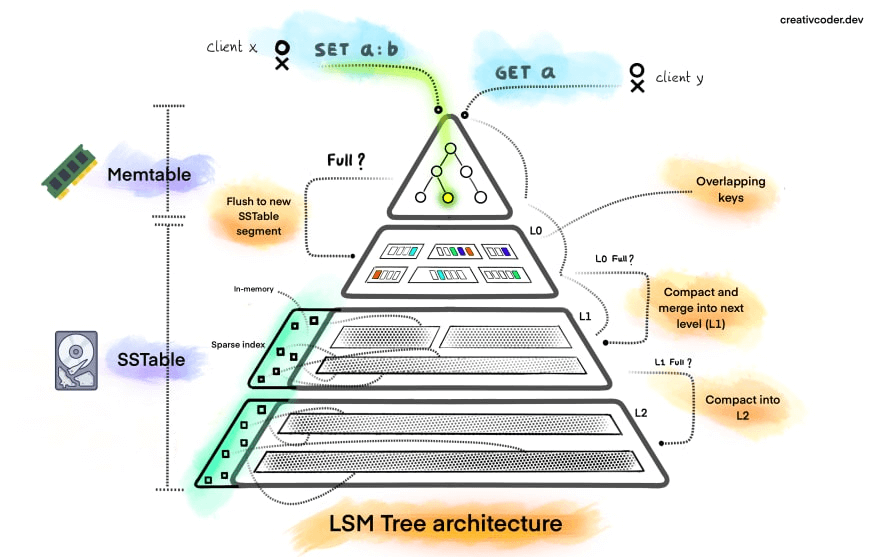
工作原理
请求路由
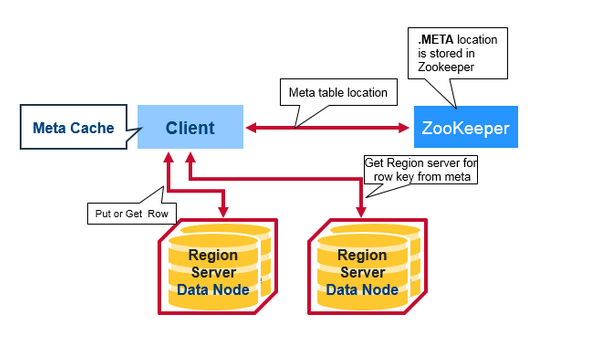
当一个请求到来时,通过 Client 访问 HBase 集群,Client 需要先和 Zookeeper 来通信,通过 ZK 查找对应存放 hbase:meta table 的 Region Server 地址。然后请求对应 RS 并根据 hbase:meta table找到 target rowkey 对应的 region 处于哪一个节点上(以上这些查询的结果都将被client 缓存起来),最后,client 访问 target region server。
老版本的 HBase 在 zookeeper 和 META 中间还有一层索引 ROOT 表,先找到 ROOT 所在的Region Server,再通过 ROOT 找到 META 表,也就是有 3 层索引。
hbase:meta 表结构
作用类似 B tree, 用于索引 Region
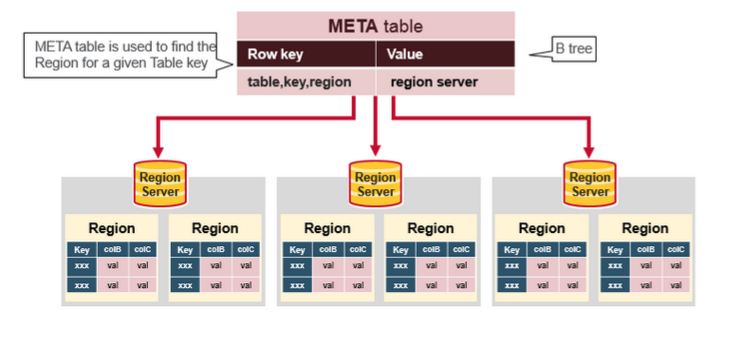
Key
- Region key of the format (
[table],[region start key],[region id])
Values
info:regioninfo(serialized HRegionInfo instance for this region)info:server(server:port of the RegionServer containing this region)info:serverstartcode(start-time of the RegionServer process containing this region)
写流程
读合并
客户端读取数据有两种方式, Get 与 Scan。 Get 是一种随机点查的方式,根据 rowkey 返回一行数据,也可以在构造 Get 对象的时候传入一个 rowkey 列表,这样一次 RPC 请求可以返回多条数据。Get 对象可以设置列与 filter,只获取特定 rowkey 下的指定列的数据、Scan 是范围查询,通过指定 Scan 对象的 startRow 与 endRow 来确定一次扫描的数据范围,获取该区间的所有数据。
读请求首先会经过上文的请求路由,定位具体的 Region Server,再是 RegionServer 处理读取请求。
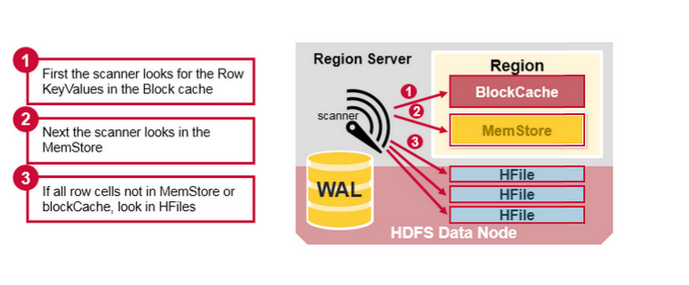
以 Scan 操作为例(Get 可以认为是特殊的 Scan,starRow endRow),读取的数据有可能在 BlockCache 、MemStore 或 HFile。所以读取数据需要合并对应的数据源(在 BlockCache 就不需要经过 IO 从 HFile 取了)。
所以要么从 BlockCache + MemStore 查到数据,要么还需要从 HFile 查。
数据删除
不会实际删除,而是通过布隆过滤器(保存在每个 HFile 中)标记,之后在数据合并时删除。
合并
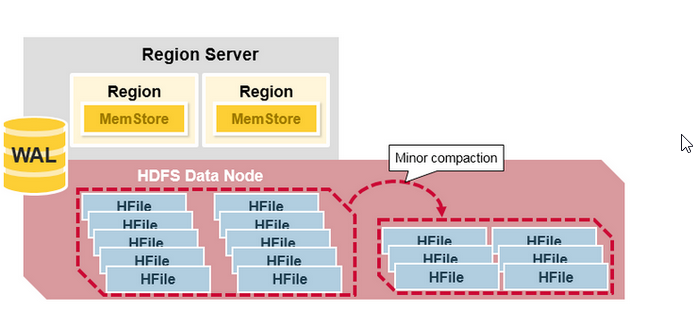
****Minor Compaction****
主要增对新增的小 HFile 文件进行合并,减少 HFile 数量,并且会进行归并排序。
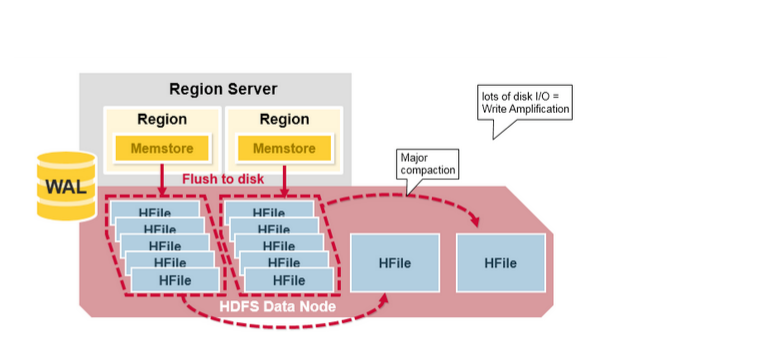
****Major Compaction****
对整个 region 下同一个 CF 对应的 HFile 进行 compact,清理过期或者被删除的数据,主要是针对老文件。由于重写磁盘文件,可能会增加 IO 和网络的压力,因此运行频率一般较低,一般一周一次。
压缩
Hbase 支持 DataBlock (HFile 存放用户数据的主要部分就是DataBlock)压缩和 HFile 文件级别的压缩。
并发操作
Hbase对于行的操作是原子的,这样的锁相对于关心型的数据库,粒度会很少,在并发的写的时候会很快。
负载均衡
另外,hbase 也有自动的负载均衡机制,会把负载较高的 region 移动到不繁忙的服务器节点上,通过 region 的移动让各个服务器达到负载均衡。
扩展性
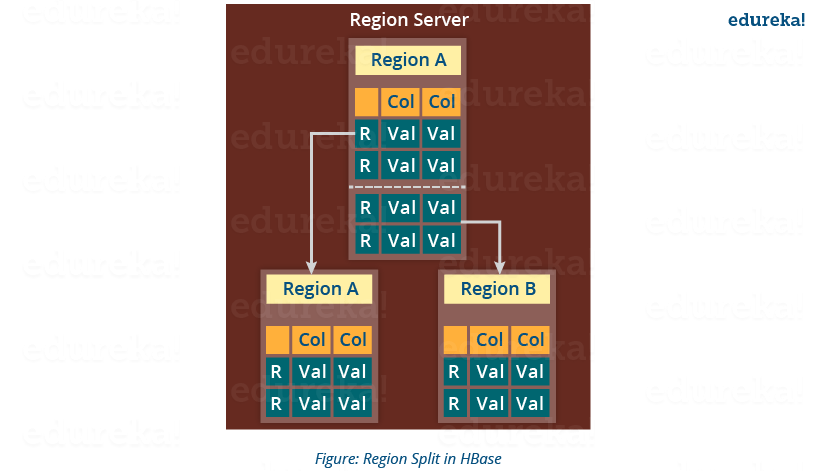
region是按照行键分的,当一个region过大,region会自动分裂,对上层是透明的,而且没有 es 坑人的 shard 分片变化要重建集群(reindex)的麻烦。
适用场景
- 大数据存储和处理:HBase可以存储PB级别的海量数据,并且支持快速的数据读写操作,可以作为大数据存储和处理平台的重要组成部分,例如企业级数据仓库、日志分析、搜索引擎等。
- 实时数据处理:HBase可以实现实时的数据存储和简单查询、不涉及复杂的关联查询,可以满足实时业务的需求。
- 时序数据处理:HBase的数据模型是面向列的,可以很方便地存储和查询大量的时序数据。同时,HBase的分布式架构可以支持海量数据的存储和处理,可以满足实时查询和分析的需求,因此特别适用于存储和管理时序数据,例如日志数据、传感器数据、监控数据等。
HBase的写入速度可以达到数百万行/秒,甚至数千万行/秒。读取速度也比较快,支持百万 QPS,RT 可以达到数十毫秒到数秒之间。具体需要根据实际情况进行性能优化。
一些最佳实践供参考。
参考
difference-between-hdfs-and-hbase