
文章目录
近期优化了订单 DB → ES 的同步链路,笔者在此总结梳理同步链路存在的挑战和方案,也希望能学习更优的方案。
背景
订单业务特点是数据量较大(分库分表),关联表较多(订单基本表、支付表、履约表、退款表、商品快照表等),不同用户对订单查询的需求不同。
用户侧可以分为客户、运营、商家。
- C端:访问量大,数据的实时性和一致性要求高,主要是订单列表和订单详情的查询;
- B端:访问量适中,对数据的实时性和一致性有一定容忍度,主要是B端展示的几个维度的分页查询;
- M端:访问量低,查询条件复杂多变,查询的数据量大,对系统可用性、数据的实时性和一致性等容忍度最高
为了支持多条件查询,我们引入了 ES。而如何将数据从 MySQL 同步到 ES 存在很多问题,常见包括如何同步、一致性问题,同步消息乱序的处理、数据如何验证等。
同步方案选择
整体上同步方式可以分为拉和推两种:
- 拉模式主要是靠轮询的方式查询最新数据,同步延时较高,例如 https://github.com/logstash-plugins/logstash-input-jdbc;
- 推模式则是通过捕捉数据变更内容进行解析,实时性高,但存在一致性问题,例如 binlog 乱序等。可选的组件包括:
- https://github.com/go-mysql-org/go-mysql-elasticsearch
功能比较简单一般不用在生产环境
-
Canal/Debezium ⇒ Kafka/RocketMQ ⇒ sync-application/Flink ⇒ ES
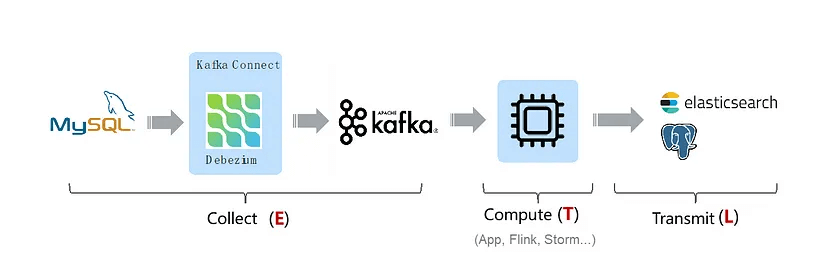
-
https://github.com/ververica/flink-cdc-connectors/
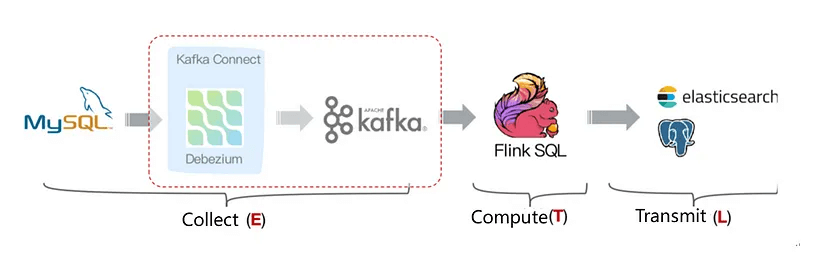
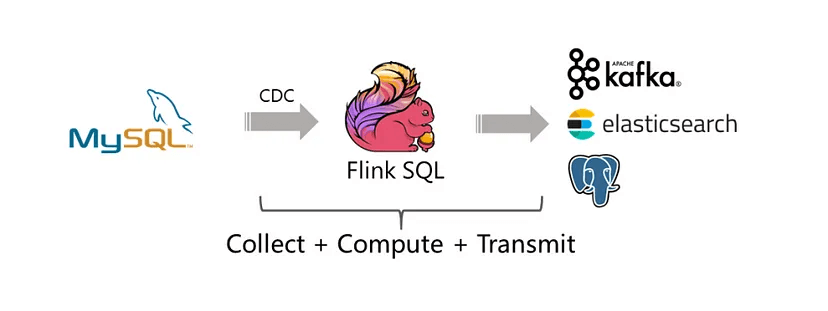
Flink-CDC 通过封装 Debezium 替代 Debezium + Kafka 组件,及 Flink 自身支持 Exactly Once,简化了链路:
- https://github.com/go-mysql-org/go-mysql-elasticsearch
比较常用的是采用监听 binlog 进行实时同步(binlog 采用 <binlog_format=ROW, binlog_image=FULL>),不侵入业务,延迟低。但需要保障一致性,例如消息乱序如何处理。
另外还需要注意避免会瞬时产生大量 binlog 的操作,比如批量 DDL,业务写入量过大等场景,一般建议变更数据量较大的情况都要分批处理。
解决乱序问题
问题的产生
binlog 本身是有序的,消息队列也能支持有序消息,例如 Canal 可以配置根据表+主键作为分区键,发送到 MQ 一个 partition 中,并以单线程消费,保证每个 partition 局部有序。但消息数据量较大时,这样存在的问题是:
- 单线程消费的速度较慢,容易造成消息堆积;
- 顺序消息在某条消息消费失败的情况下,对应分区内的后续消息就会全部堆积,也会造成数据同步发生较大延迟。
不依赖顺序队列解决
实时查方案
之所以 binlog 消息乱序会有问题,是由于我们直接解析 binlog 数据作为同步的数据源,乱序会造成老数据覆盖新数据。那么我们可以不依赖 binlog 数据,而是通过 binlog 解析订单号然后去订单表里查询或调用订单查询接口,这样就总是能查到最新的数据,看起来非常完美。这也是我们老版本的方案。
但这个方案存在几个问题:
- 对数据库造成读压力;
- 数据库如果是读写分离架构,由于主从延迟的存在,导致数据可能不是最新的(可以读从库 binlog,但会增加同步延迟)。
其实在数据量不大的情况下,这个方案也是比较合适的。
另外还有通过 Logstash 来进行同步 的方案,它是通过不断轮询查的方式进行同步,实时性差。
版本号方案
采用版本号的方式解决乱序问题,对大于当前版本的数据才进行写入,小于等于的直接丢弃。
- 单表场景
对于单表场景,直接使用ElasticSearch 版本号支持便能够解决同步消息乱序的问题。通过乐观锁的方式实现,满足原子性。
- 内部版本号
数据查询
curl -XGET 'http://localhost:9200/designs/shirt/1' { "_index": "designs", "_type": "shirt", "_id": "1", "_version": 4, // 自带版本号,每次自增1 "exists": true, "_source": { "name": "elasticsearch", "votes": 1002 } }数据更新
curl -XPOST 'http://localhost:9200/designs/shirt/1?version=4' -d' { "name": "elasticsearch", "votes": 1003 }' // 若当前版本号不为4,则更新失败ES 6.0.0 之后写操作不支持以
_version作为乐观锁,而是提示使用if_seq_no和if_primary_term,例如:
http://localhost:9200/designs/shirt/1?if_seq_no=2&if_primary_term=2. - 外部版本号
内部版本号虽然能按照指定的序列进行更新操作。但是存在明显的问题:
- 数据写入时,版本号应该以业务数据为准,而不是通过 ES 自己生成;
- 哪怕支持业务指定版本号,但由于同步数据顺序不确定,无法明确指定版本号进行更新。
所以 ES 提供了外部版本号(1:2^63-1整数)支持,如下,指定
version_type=externalcurl -XPOST 'http://localhost:9200/designs/shirt/1?version=526&version_type=external' -d' { "name": "elasticsearch", "votes": 1003 }'不同于内部版本号,“当且仅当存储的 version = xx 时才更新成功,version 自增 1“
外部版本号实现的语义是,“当且仅当存储的 version < xx 时才更新成功,version 更新为 xx”
重要提示:使用 external 版本控制时,请确保始终将当前 version(和 version_type)添加到任何索引、更新或删除调用中。否则,Elasticsearch 将使用它的内部系统来处理该请求,这会导致错误地递增版本号。
使用这种方式则需要在业务数据库增加版本号字段,或者使用修改时间(修改时间依赖系统时钟,建议还是使用版本号字段)作为版本号。
- 内部版本号
-
多表场景
在订单场景下,我们需要满足的是多表的场景,订单包含多个表数据,如订单base表 + 订单支付表 + 订单退款表 + 商品快照表等,而 ES 版本号仅支持 doc 维度,无法满足需求。
这里可以利用 Hbase ,支持每列携带版本号(timestamp):
org.apache.hadoop.hbase.client.Put#addColumn(family, qualifier, timestamp, value)通过 HBase 可以对每个单表(对应 HBase 列)可以指定版本号保障幂等更新,再对 HBase 完整的宽表行增加一个自增版本号字段,用于作为 ES doc 的版本号,最后将 HBase 数据写入ES,可参考有赞订单同步方案。

一致性校验
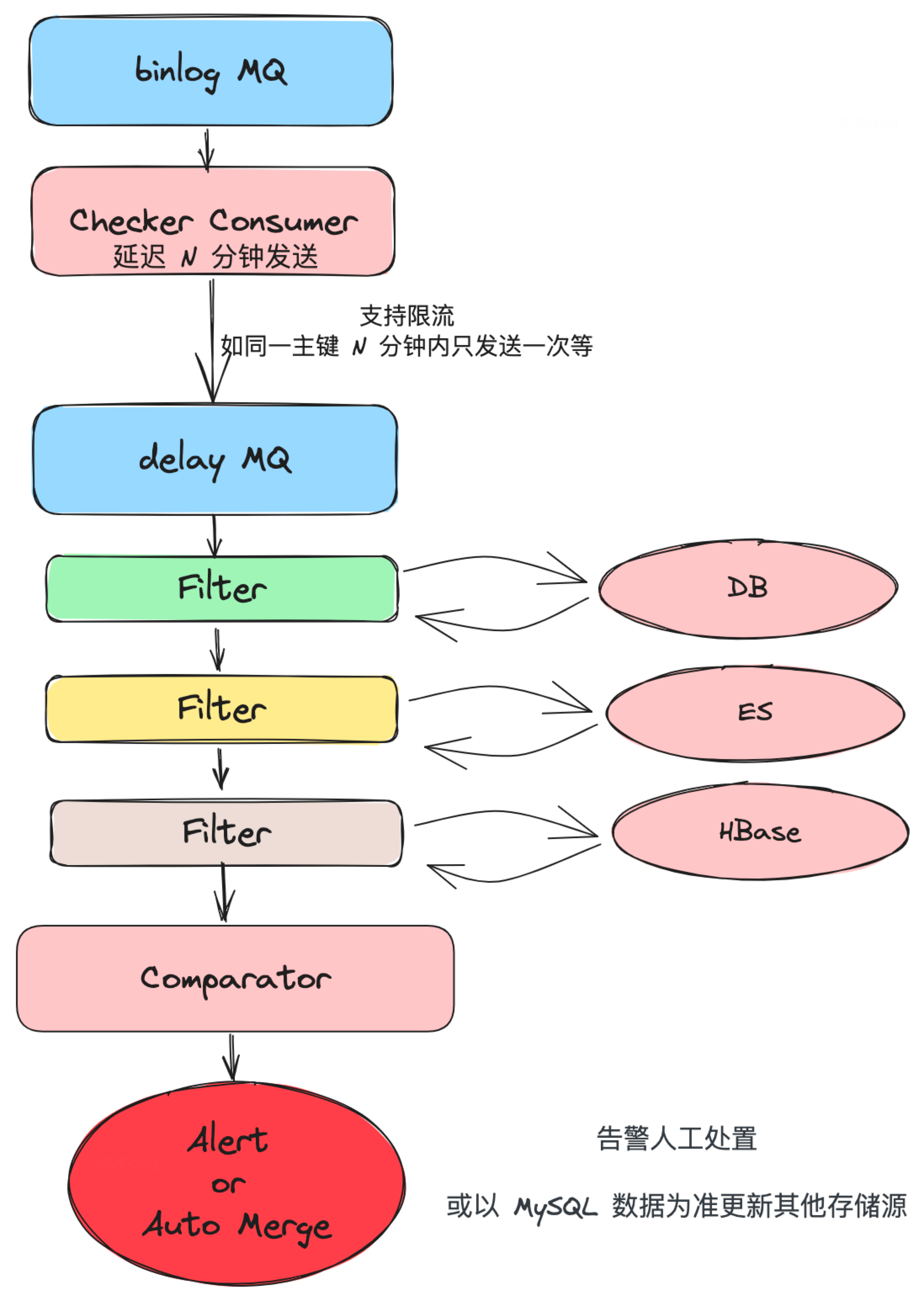
我们无法保证同步链路 100% 没有问题,所以需要通过自动校验的方式进行监控,例如数据是否一致、同步是否产生较高延迟等。
由于数据源是 MySQL,我们可以利用 binlog 触发延时消息进行N方数据对比,若发生不一致或延时较高,可以进行报错或利用 MySQL 数据更新其他存储组件数据。
更多优化点
读性能优化
- ES + HBase:由于 ES 需要对所有字段做倒排索引,在字段较多的情况下,占用较多内存,影响数据的写入效率。所以可以采用 HBase 存储全量字段,ES 只作为二级索引存在,保存需要查询的字段和 HBase 的 rowkey 。
- ES + Redis + HBase:HBase 读场景下 RT 通常在是毫秒级别,而 Redis 能够达到几微秒。由于加上了二级缓存,所以可以在中间加上 Redis 作为缓存提高热点数据查询效率。
配置化
数据同步链路上已经非常固定,可以通过配置 source 和 sink 对应的表结构映射、聚合逻辑来联通上下游数据,即把计算需要的内容配置化,以支持快速建立同步链路,实际上对应简单的单表同步,业界基本都是一条 flink sql 结合 cdc 就可以搞定。
总结
以上是笔者目前了解到的数据同步的一些方案,虽然已经有强大的轮子,但是细节上还是需要我们考虑如何处理。目前笔者采用的方案也是解析binlog同步+延时消息校验补偿的方式进行,极端场景下有一定延时同步,但链路比较简单易于维护,基本满足最终一致。没有完美的方案,只有当下最合适的方案。
另外以上只是增量同步的方案,全量同步方案下次更新。
参考:
how-to-keep-elasticsearch-synchronized-with-a-relational-database-using-logstash