
文章目录
Dubbo 支撑高并发离不开线程池的设计,本篇笔者总结 Dubbo 中的线程池模型和配置。主要分为 IO 线程池和业务线程池。
本文基于 Dubbo 2.7.3
Netty 线程池
Consumer
消费端 IO 线程池相对简单,消费端在进行连接时创建 NettyClient,并绑定线程池中的线程:
// 属于 NettyClient class 静态变量
private static final NioEventLoopGroup nioEventLoopGroup
= new NioEventLoopGroup(Constants.DEFAULT_IO_THREADS, new DefaultThreadFactory("NettyClientWorker", true));
int DEFAULT_IO_THREADS = Math.min(Runtime.getRuntime().availableProcessors() + 1, 32);
// 线程数默认 CPU 核心数 + 1,最大 32
...
// org.apache.dubbo.remoting.transport.netty4.NettyClient#doOpen
protected void doOpen() throws Throwable {
final NettyClientHandler nettyClientHandler = new NettyClientHandler(getUrl(), this);
bootstrap = new Bootstrap();
bootstrap.group(nioEventLoopGroup)
.option(ChannelOption.SO_KEEPALIVE, true)
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
//.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, getTimeout())
.channel(NioSocketChannel.class);
...
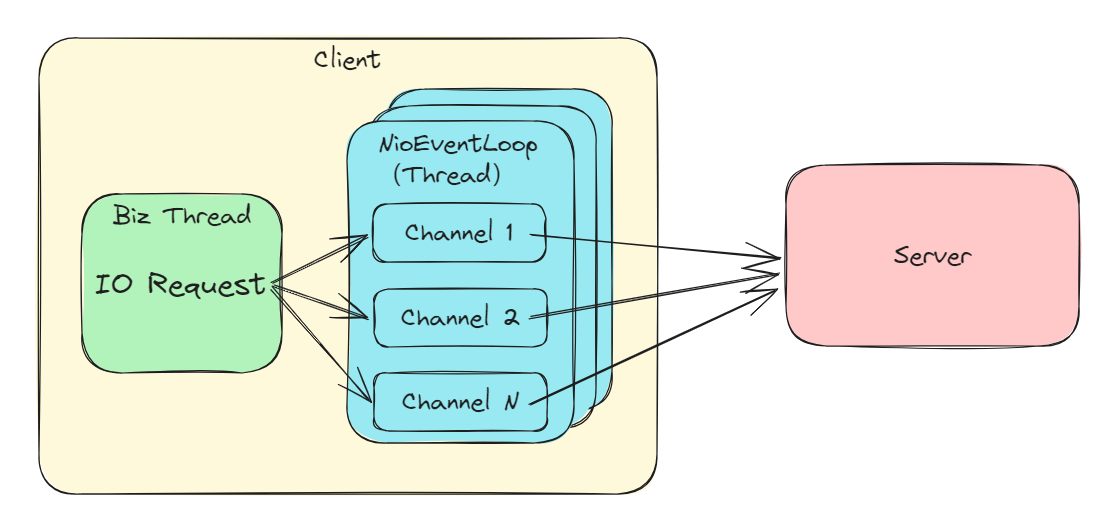
每个 Channel 绑定一个线程,通过线程池分配。Channel 绑定线程代码:
io.netty.bootstrap.Bootstrap#doResolveAndConnect
→ io.netty.bootstrap.AbstractBootstrap#initAndRegister
// io.netty.bootstrap.AbstractBootstrap#initAndRegister
Channel channel = null;
try {
// 新建 NioSocketChannel
channel = channelFactory.newChannel();
init(channel);
} catch (Throwable t) {
...
}
// group 即 nioEventLoopGroup 线程池
ChannelFuture regFuture = config().group().register(channel);
...
// io.netty.channel.MultithreadEventLoopGroup#register(io.netty.channel.Channel)
public ChannelFuture register(Channel channel) {
return next().register(channel);
// 这里通过 GenericEventExecutorChooser 或 PowerOfTwoEventExecutorChooser 的 next() 方法选择线程
// 选择的方式是通过自增ID 取模线程池大小(若大小为2的幂次则通过与运算优化)。
}
// 每个 channel 会绑定一个 NioEventLoop,NioEventLoop 可以认为是一个只有一个线程的线程池
// 其执行 io.netty.channel.nio.NioEventLoop#run不断地执行任务。
简单表达流程如下:
Provider
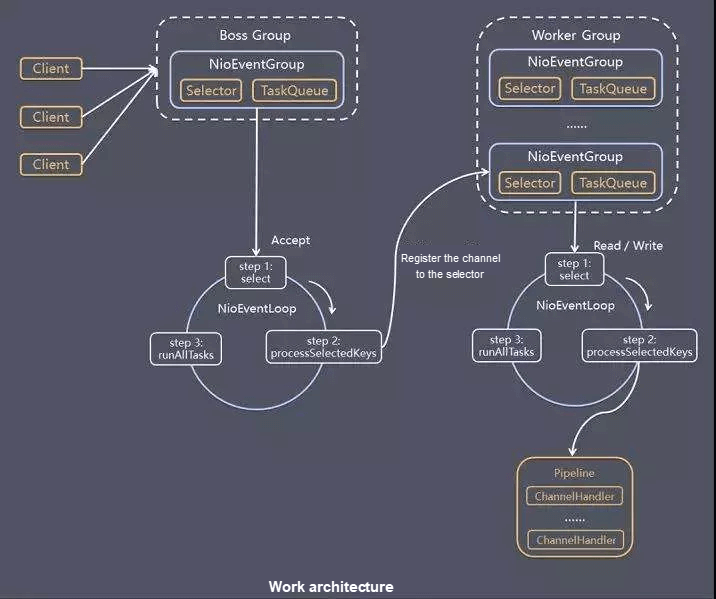
Dubbo 默认采用的是主从 Reactor 多线程模型,NettyServer 使用两级线程池,其中EventLoopGroup(boss)主要用来接收客户端的链接请求,并把完成TCP三次握手的连接分发给EventLoopGroup(worker)来处理,把 boss 和 worker 线程组称为 I/O 线程。
Netty Server Thread Model
代码 org.apache.dubbo.remoting.transport.netty4.NettyServer#doOpen
bootstrap = new ServerBootstrap();
bossGroup = new NioEventLoopGroup(1, new DefaultThreadFactory("NettyServerBoss", true));
workerGroup = new NioEventLoopGroup(getUrl().getPositiveParameter(IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS),
new DefaultThreadFactory("NettyServerWorker", true)); // worker 线程数默认 CPU 核心数 + 1,最大 32
final NettyServerHandler nettyServerHandler = new NettyServerHandler(getUrl(), this);
channels = nettyServerHandler.getChannels();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childOption(ChannelOption.TCP_NODELAY, Boolean.TRUE)
.childOption(ChannelOption.SO_REUSEADDR, Boolean.TRUE)
.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// FIXME: should we use getTimeout()?
int idleTimeout = UrlUtils.getIdleTimeout(getUrl());
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyServer.this);
ch.pipeline()//.addLast("logging",new LoggingHandler(LogLevel.INFO))//for debug
.addLast("decoder", adapter.getDecoder())
.addLast("encoder", adapter.getEncoder())
.addLast("server-idle-handler", new IdleStateHandler(0, 0, idleTimeout, MILLISECONDS))
.addLast("handler", nettyServerHandler);
}
});
...
}
- Boss 线程
- 作用:accept 连接,将接收到的连接注册到一个 worker 线程中
- 个数:正常一个 Server 一个 Boss 线程(即服务端每绑定一个端口,开启一个 Boss 线程)
- Worker 线程
- 作用:处理注册在其中的连接的各种 io 事件(读写)。
- 个数:CPU 核心数 + 1,最大 32
另外:一个 worker 线程可以注册多个 connection,一个 connection 只能注册在一个worker线程上。
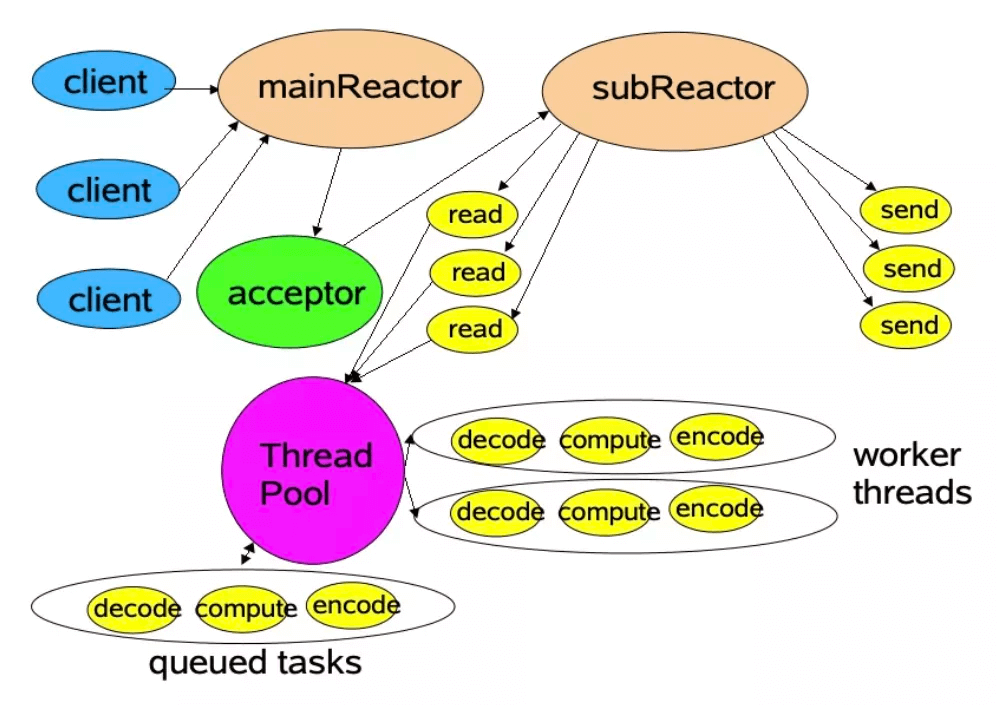
主从 Reactor 模型
业务线程池
Consumer
Consumer 端的线程池,是在初始化 Client (如NettyClient)时,通过与指定的 provider url 建立连接前创建的,默认是 cached threadpool。代码
org.apache.dubbo.remoting.Transporter#connect
→ org.apache.dubbo.remoting.transport.netty4.NettyClient#NettyClient
→org.apache.dubbo.remoting.transport.AbstractClient#wrapChannelHandler
// 在前面的代码中,会通过
// url.addParameterIfAbsent(THREADPOOL_KEY, DEFAULT_CLIENT_THREADPOOL)
// 指定 threadpool SPI 采用 cached 线程池
public class CachedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
String name = url.getParameter(THREAD_NAME_KEY, DEFAULT_THREAD_NAME);
int cores = url.getParameter(CORE_THREADS_KEY, DEFAULT_CORE_THREADS);
int threads = url.getParameter(THREADS_KEY, Integer.MAX_VALUE);
int queues = url.getParameter(QUEUES_KEY, DEFAULT_QUEUES);
int alive = url.getParameter(ALIVE_KEY, DEFAULT_ALIVE);
return new ThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}
// 默认核心线程池数为0,最大线程池数 Integer.MAX_VALUE,采用 SynchronousQueue 队列
// 线程超时时间为1分钟,即非活跃线程1分钟后被回收。
Provider
Provider 端的线程池,是在初始化 Server(如 NettyServer)时,在包装 channelHandler 时生成的,默认走的 fixed threadpool。代码 org.apache.dubbo.remoting.transport.netty4.NettyServer#NettyServer
public class FixedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
String name = url.getParameter(THREAD_NAME_KEY, DEFAULT_THREAD_NAME);
int threads = url.getParameter(THREADS_KEY, DEFAULT_THREADS);
int queues = url.getParameter(QUEUES_KEY, DEFAULT_QUEUES);
return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}
// 默认200个线程,超时时间为0以至于线程会一直存在
线程池间交互
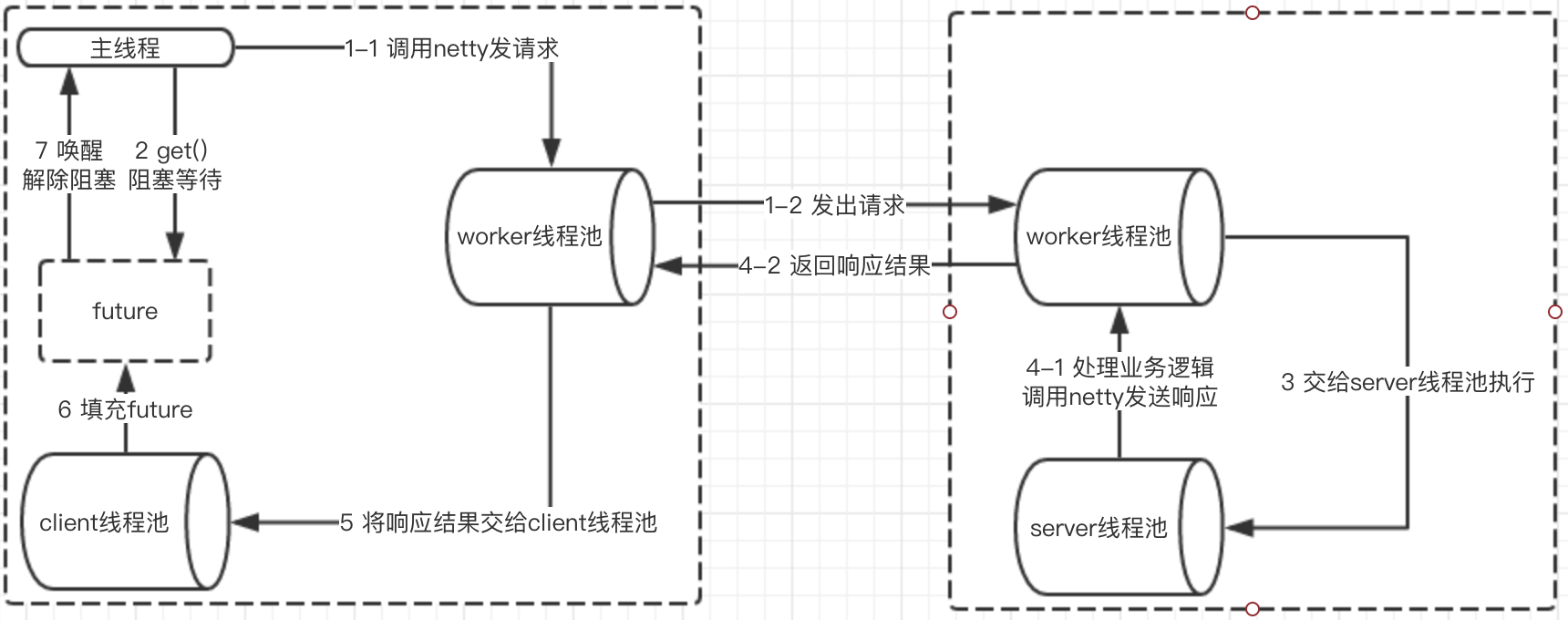
Provider 端默认的 All Dispatcher 模型:
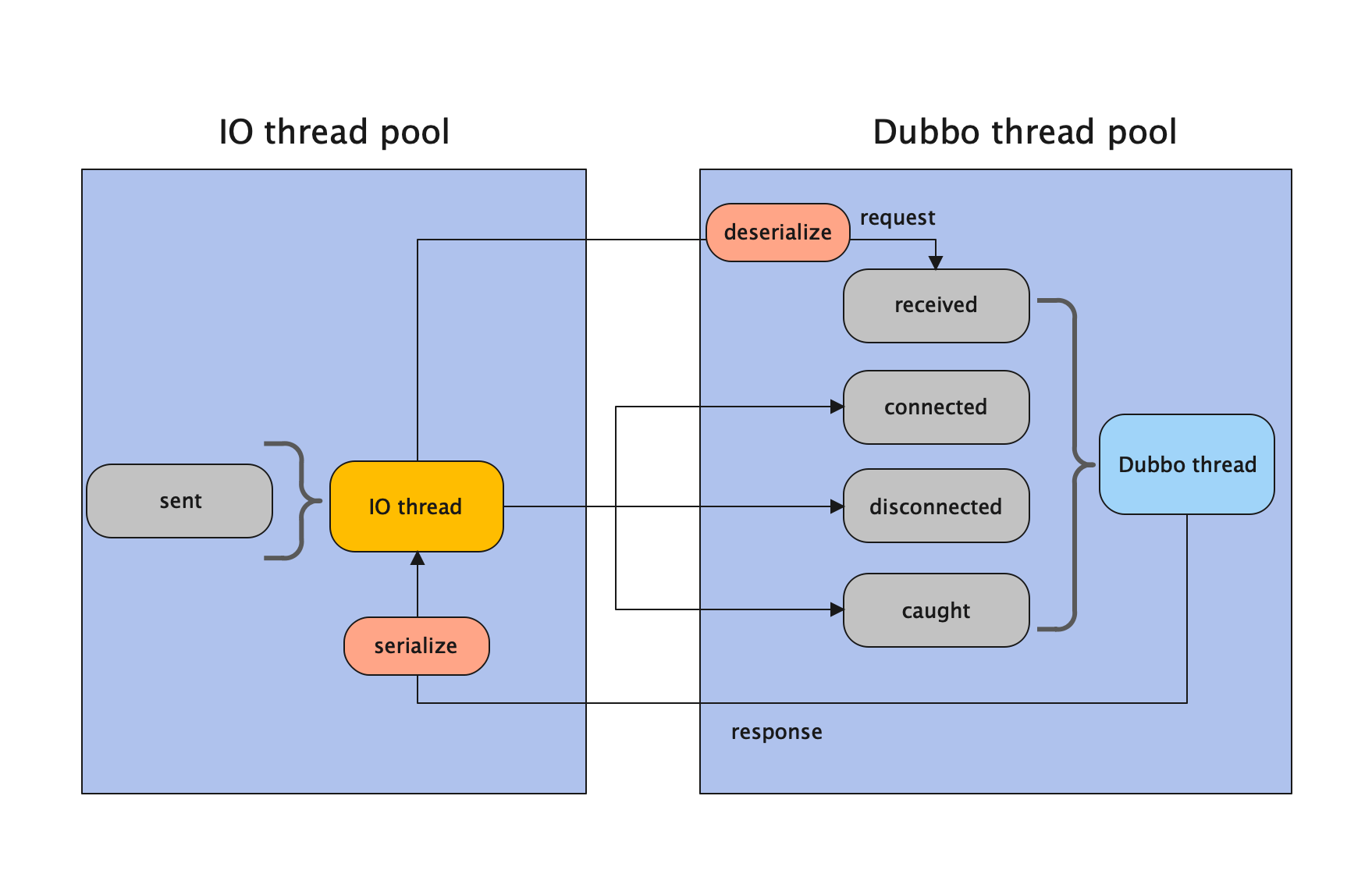
细节
细节1:消费端创建线程池过程(时机)?
Cunsumer 端在生成调用方动态代理时进行 Client(如 NettyClient)初始化,重点是下面的getClients() 方法:
// org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol#protocolBindingRefer
@Override
public <T> Invoker<T> protocolBindingRefer(Class<T> serviceType, URL url) throws RpcException {
optimizeSerialization(url);
// create rpc invoker.
DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url, getClients(url), invokers);
invokers.add(invoker);
return invoker;
}
// org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol#getClients
private ExchangeClient[] getClients(URL url) {
// whether to share connection
boolean useShareConnect = false;
int connections = url.getParameter(CONNECTIONS_KEY, 0);
List<ReferenceCountExchangeClient> shareClients = null;
// if not configured, connection is shared, otherwise, one connection for one service
if (connections == 0) {
useShareConnect = true;
/**
* The xml configuration should have a higher priority than properties.
*/
String shareConnectionsStr = url.getParameter(SHARE_CONNECTIONS_KEY, (String) null);
connections = Integer.parseInt(StringUtils.isBlank(shareConnectionsStr) ? ConfigUtils.getProperty(SHARE_CONNECTIONS_KEY,
DEFAULT_SHARE_CONNECTIONS) : shareConnectionsStr);
shareClients = getSharedClient(url, connections);
}
ExchangeClient[] clients = new ExchangeClient[connections];
for (int i = 0; i < clients.length; i++) {
if (useShareConnect) {
clients[i] = shareClients.get(i);
} else {
clients[i] = initClient(url);
}
}
return clients;
}
// org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol#initClient
private ExchangeClient initClient(URL url) {
// client type setting.
String str = url.getParameter(CLIENT_KEY, url.getParameter(SERVER_KEY, DEFAULT_REMOTING_CLIENT));
url = url.addParameter(CODEC_KEY, DubboCodec.NAME);
// enable heartbeat by default
url = url.addParameterIfAbsent(HEARTBEAT_KEY, String.valueOf(DEFAULT_HEARTBEAT));
// BIO is not allowed since it has severe performance issue.
if (str != null && str.length() > 0 && !ExtensionLoader.getExtensionLoader(Transporter.class).hasExtension(str)) {
throw new RpcException("Unsupported client type: " + str + "," +
" supported client type is " + StringUtils.join(ExtensionLoader.getExtensionLoader(Transporter.class).getSupportedExtensions(), " "));
}
ExchangeClient client;
try {
// connection should be lazy
// 配置 Lazy 实现第一次调用时才连接服务端
if (url.getParameter(LAZY_CONNECT_KEY, false)) {
client = new LazyConnectExchangeClient(url, requestHandler);
} else {
client = Exchangers.connect(url, requestHandler);
}
} catch (RemotingException e) {
throw new RpcException("Fail to create remoting client for service(" + url + "): " + e.getMessage(), e);
}
return client;
}
经过 org.apache.dubbo.remoting.exchange.Exchangers#connect(org.apache.dubbo.common.URL, org.apache.dubbo.remoting.exchange.ExchangeHandler)
→ org.apache.dubbo.remoting.exchange.support.header.HeaderExchanger#connect
→ org.apache.dubbo.remoting.Transporters#connect(org.apache.dubbo.common.URL, org.apache.dubbo.remoting.ChannelHandler...)
→ org.apache.dubbo.remoting.transport.netty4.NettyTransporter#connect
最终创建 Cunsumer 端的 NettyClient 线程池绑定到的 Netty 的 bootstrap,代码:org.apache.dubbo.remoting.transport.AbstractClient#AbstractClient
→ org.apache.dubbo.remoting.transport.netty4.NettyClient#doOpen
细节2:消费端反序列化由哪个线程池负责?
Dubbo官网对于消费端线程池的描述是对于请求 / 响应的反序列化是在业务线程池进行的。然而在笔者某次追踪问题时发现,实际上在 2.7.5 之前(笔者部门采用2.7.3),反序列化操作实际上是在 IO 线程中执行的。代码:
org.apache.dubbo.rpc.protocol.dubbo.DubboCodec#decodeBody
// 该代码是 IO 线程执行的
DecodeableRpcResult result;
if (channel.getUrl().getParameter(DECODE_IN_IO_THREAD_KEY, DEFAULT_DECODE_IN_IO_THREAD)) {
result = new DecodeableRpcResult(channel, res, is,(Invocation) getRequestData(id), proto);
// 解码(包含反序列化)
result.decode();
} else {
result = new DecodeableRpcResult(channel, res,new UnsafeByteArrayInputStream(readMessageData(is)),
(Invocation) getRequestData(id), proto);
}
data = result;
以上代码在 2.7.3 和 2.7.5 版本中是一样的,都是通过获取 DECODE_IN_IO_THREAD_KEY 配置,判断是否执行解码操作,唯一的不同是DEFAULT_DECODE_IN_IO_THREAD这个默认值:
在 2.7.3 为
boolean DEFAULT_DECODE_IN_IO_THREAD = true;
在 2.7.5 为
boolean DEFAULT_DECODE_IN_IO_THREAD = false;
所以实际上 2.7.5 之前的版本,反序列化都是在 IO 线程中执行的,官网描述有误。
引用官网对于 2.7.5 之前的消费端线程池模型描述:
- 业务线程发出请求,拿到一个 Future 实例。
- 业务线程紧接着调用 future.get 阻塞等待业务结果返回。
- 当业务数据返回后,交由独立的 Consumer 端线程池进行反序列化等处理,并调用 future.set 将反序列化后的业务结果置回。
- 业务线程拿到结果直接返回。
细节3:消费端线程池问题及 Dubbo 2.7.5 是如何优化的?
问题
对于 2.7.5 之前,dubbo 的逻辑是一个连接就会新建一个CachedThreadPool,且线程池内线程数量无上限,对于并发数较大且提供者处理缓慢的情况下会出现消费端线程数过多的问题;另外当一个 provider 下线时会销毁 executor, 当请求另外的 provider 时重建,github 上也有对应的 issue#2013 Need a limited Threadpool in consumer side ,https://github.com/apache/dubbo/issues/7054。
v2.7.5 前:
消费者线程池模型:
1. 共享连接(connections=0)场景:
简版数据结构:<host:port, CachedThreadPool(corePoolSize)>
线程池数量:sum(host:port)
线程池数量示例:假设提供者节点有6个,则消费者应用会创建6个 CachedThreadPool 实例。
- 配置连接数(connections>0)场景:
简版数据结构:ExchangeClient[connections]<service-host:port, CachedThreadPool(corePoolSize)>
线程池数量:sum(host:port * connections)
线程池数量示例:假设提供者节点有6个,且某个服务配置了 connections=50,则消费者应用对于这个服务会创建 6*50=300个 CachedThreadPool 实例。
提供者线程池模型:
1.全局使用一个线程池实例。
优化方案
于是 dubbo 2.7.5 之后,dubbo 社区对于消费端线程池进行了优化,引入 ThreadlessExecutor(伪线程池)用于同步调用场景,每次调用新建一个 ThreadlessExecutor,其构造方法传入的线程池是 CachedThreadPool(该线程池为全局共享)
参考 https://github.com/apache/dubbo/pull/7109)
// org.apache.dubbo.rpc.protocol.dubbo.DubboInvoker#doInvoke
// 发送同步请求时,传入 ThreadlessExecutor 与请求绑定 (通过 DefaultFuture#executor)
ExecutorService executor = getCallbackExecutor(getUrl(), inv);
CompletableFuture<AppResponse> appResponseFuture =
currentClient.request(inv, timeout, executor).thenApply(obj -> (AppResponse) obj);
// save for 2.6.x compatibility, for example, TraceFilter in Zipkin uses com.alibaba.xxx.FutureAdapter
FutureContext.getContext().setCompatibleFuture(appResponseFuture);
AsyncRpcResult result = new AsyncRpcResult(appResponseFuture, inv);
result.setExecutor(executor);
return result;
// org.apache.dubbo.rpc.protocol.AbstractInvoker#getCallbackExecutor
protected ExecutorService getCallbackExecutor(URL url, Invocation inv) {
ExecutorService sharedExecutor = ExtensionLoader.getExtensionLoader(ExecutorRepository.class).getDefaultExtension().getExecutor(url);
if (InvokeMode.SYNC == RpcUtils.getInvokeMode(getUrl(), inv)) {
return new ThreadlessExecutor(sharedExecutor);
} else {
return sharedExecutor;
}
}
收到服务端响应后,仅暂存任务,但不处理,如下(以 AllChannelHandler 为例):
// org.apache.dubbo.remoting.transport.dispatcher.all.AllChannelHandler#received
@Override
public void received(Channel channel, Object message) throws RemotingException {
// 根据响应 ID 获取之前关联请求的线程池,即 ThreadlessExecutor
ExecutorService executor = getPreferredExecutorService(message);
try {
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
if(message instanceof Request && t instanceof RejectedExecutionException){
sendFeedback(channel, (Request) message, t);
return;
}
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}
// org.apache.dubbo.common.threadpool.ThreadlessExecutor#execute
// 正常响应或者响应超时都会调用
@Override
public void execute(Runnable runnable) {
synchronized (lock) {
// 判断业务线程是否还在等待响应结果
if (!waiting) {
// 不等待,则直接交给共享线程池处理任务
sharedExecutor.execute(runnable);
} else {
// 放进阻塞队列,采用 LinkedBlockingQueue 无界队列
queue.add(runnable);
}
}
}
当业务线程需要获取返回时,此时会调用 waitAndDrain 方法从队列获取任务并进行真正执行。
org.apache.dubbo.rpc.protocol.AsyncToSyncInvoker#invoke
→org.apache.dubbo.rpc.Result#get(long, java.util.concurrent.TimeUnit)
@Override
public Result get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {
if (executor != null && executor instanceof ThreadlessExecutor) {
ThreadlessExecutor threadlessExecutor = (ThreadlessExecutor) executor;
// 取队列中的任务并执行
threadlessExecutor.waitAndDrain();
}
return responseFuture.get(timeout, unit);
}
// org.apache.dubbo.common.threadpool.ThreadlessExecutor#waitAndDrain()
public void waitAndDrain() throws InterruptedException {
/**
* Usually, {@link #waitAndDrain()} will only get called once. It blocks for the response for the first time,
* once the response (the task) reached and being executed waitAndDrain will return, the whole request process
* then finishes. Subsequent calls on {@link #waitAndDrain()} (if there're any) should return immediately.
*
* There's no need to worry that {@link #finished} is not thread-safe. Checking and updating of
* 'finished' only appear in waitAndDrain, since waitAndDrain is binding to one RPC call (one thread), the call
* of it is totally sequential.
*/
// 检测当前ThreadlessExecutor状态
if (finished) {
return;
}
// 取阻塞队列任务
Runnable runnable = queue.take();
synchronized (lock) {
// 标记不再等待
waiting = false;
// 执行任务
runnable.run();
}
// 如果阻塞队列中还有其他任务,也需要一并执行
runnable = queue.poll();
while (runnable != null) {
try {
runnable.run();
} catch (Throwable t) {
logger.info(t);
}
runnable = queue.poll();
}
// mark the status of ThreadlessExecutor as finished.
finished = true;
}
总结下 dubbo 2.7.5 的ThreadlessExecutor 目的就是为了减少消费端的线程数量过多的问题,利用调用 ThreadlessExecutor 的线程,即业务线程自行完成反序列化、解码、业务逻辑处理。
参考
Essential Technologies for Java Developers: I/O and Netty
https://cloud.tencent.com/developer/article/1602118