
背景
最近维护公司某C端工程,发现项目偶发 CPU idle 掉底告警且伴随几个不相关接口响应慢,响应时间p99达到 5000+ ms(正常rt p99 在1000ms以内),且无规律,难以复现所以也并无现场。
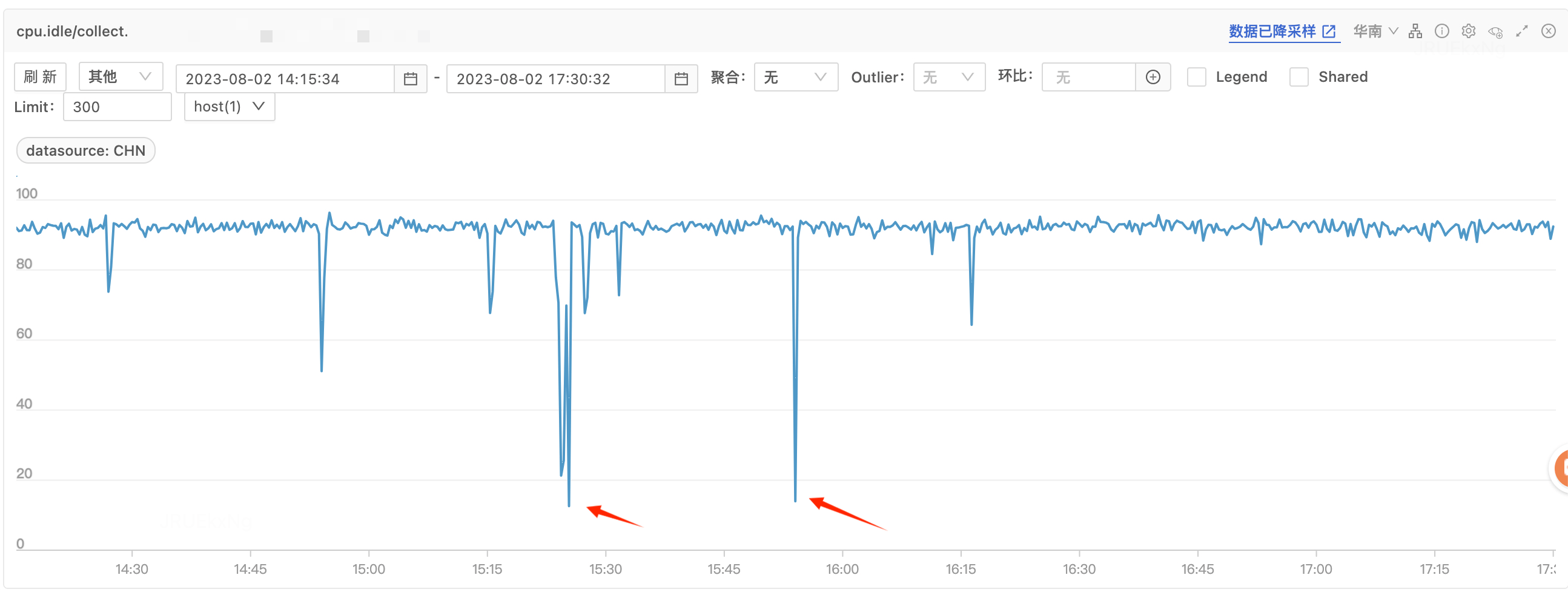
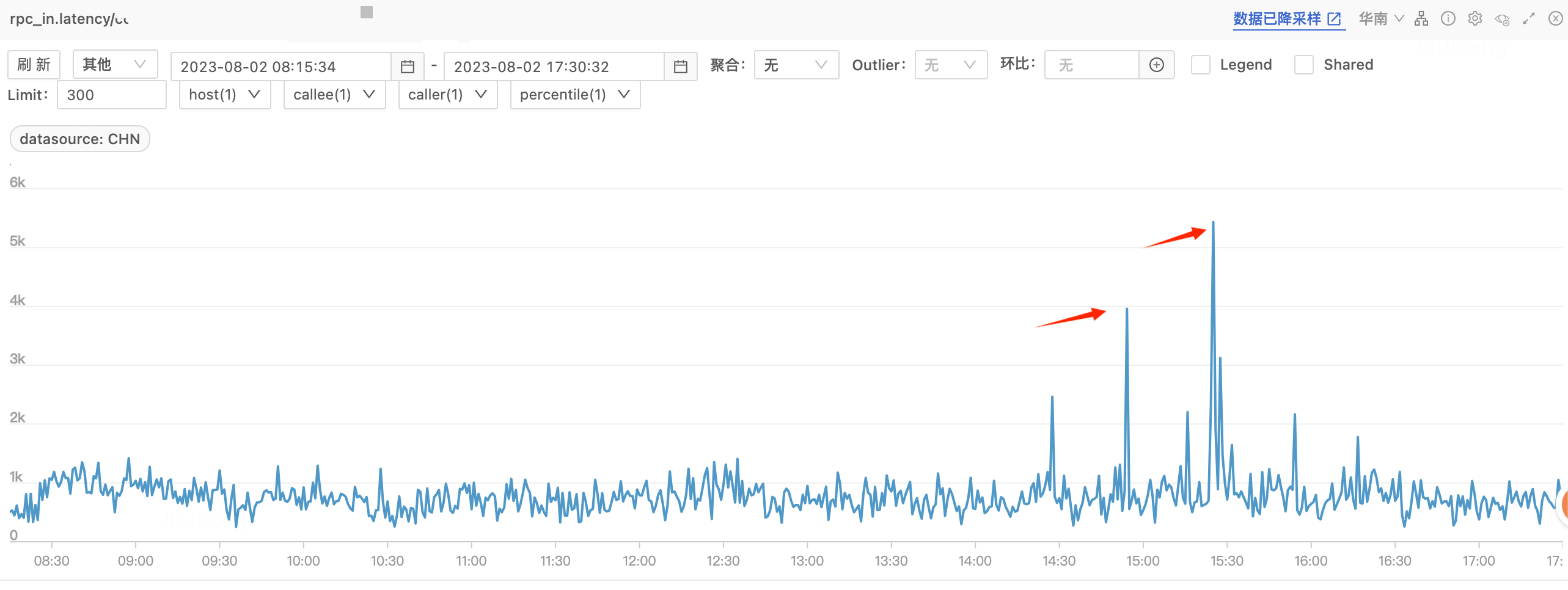
CPU 掉底时间上与RT毛刺时间拟合
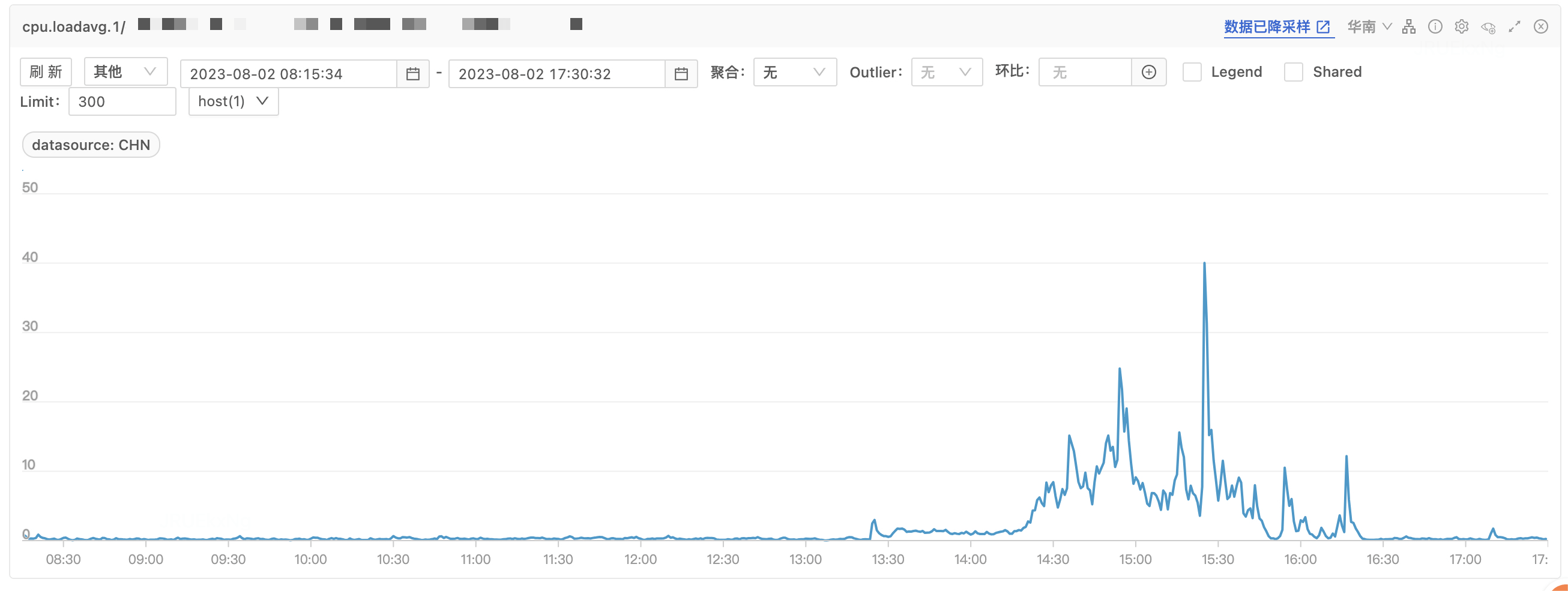
CPU load 同时出现毛刺
- CPU idle 和 load 关系
CPU load: CPU 负载指的是正在运行和准备好运行的进程的总数,基于/proc/loadavg进行统计。
CPU idle: CPU 空闲率是基于/proc/stat计算出来的。指的是CPU处于空闲状态时间比例,从时间的角度衡量CPU的空闲程度。 CPU 总时间 = 用户态执行时间 + 内核态执行时间 + 空闲系统进程执行时间。
则 CPU idle = CPU执行空闲的时间 / CPU总的执行时间。例如:银行窗口每次只能接待一人(单核),某时刻来了5个人,即1人办业务,4人等待。但在给一个人办业务的10分钟内,业务员要抽烟2分钟,实际办业务8分钟。
那么此时,load = 5, idle = 1 – 8/10 = 20 %二者关系:1. CPU密集型的程序,那么CPU利用率会比较高(空闲率低),Load一般也会比较高。
- I/O密集型的程序,可能看到CPU的%user, %system都不高,%iowait可能会有点高,此时Load通常比较高。使用率一般不高。同理,程序读写慢速I/O设备(如磁盘、NFS)比较多时,Load可能会比较,而CPU利用率不一定高。这种情况,还经常发生在系统内存不足并开始使用swap的时候,Load一般会比较高,而CPU使用率并不高。
对应时段 QPS、磁盘IO、内存、GC 都没有异常。平时 CPU idle 在 60-80% 之间,由于该工程接口直接 to C,需要解决该问题避免影响用户体验。
常见 CPU 100% 场景
- 代码中有比较耗时的计算
- 频繁 GC
- 并发量提升
- 资源竞争激烈(如死锁自旋的情况)
- 硬件故障
排查过程
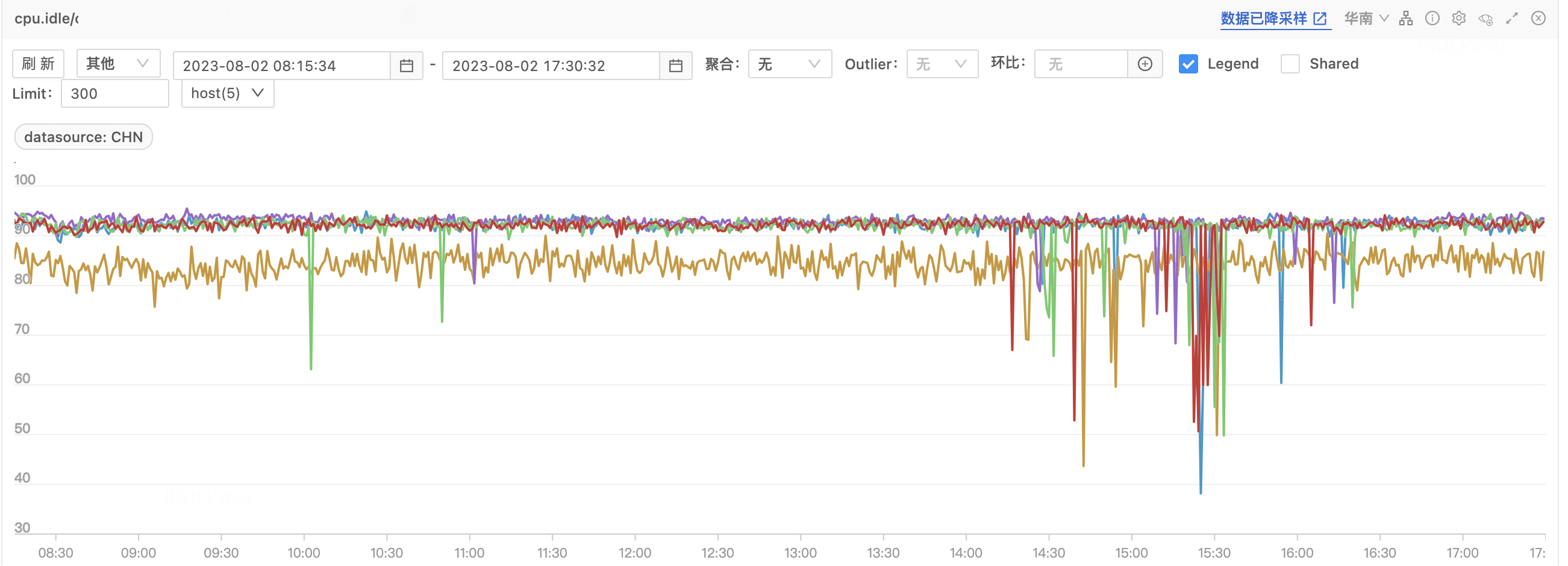
对比多个实例监控,曲线波动基本一致,基本排除物理机故障导致。
且从监控看到 GC 和流量没有较大波动,怀疑是代码中有耗时计算。
由于没有现场,所以只能通过排查事故发生时间段内的日志来定位。
具体过程:
- 排查 15:20 ~ 15:30 内高耗时的操作(大于1500ms)
sed -n '/2023-08-02T15:20:*/,/2023-08-02T15:30:*/p' metric_trace.log > slow.log grep proc_time slow.log|awk -F'\\\|\\\|' '{gsub(/proc_time=/,""); print 2,7,18}' |awk '{if(3>1500) print $3}' - 筛选后发现除了常见的链路的请求外,出现几个删除 Redis 缓存的操作,耗时高达5000ms+,并且删除的 Key 数量达到 5000K+,正常业务逻辑不应该也不允许出现这种操作,定位问题代码
keys.parallelStream().forEach(key -> { if (redisTemplate.hasKey(key)) { redisTemplate.delete(key); } });这里最多会循环 1W 次,逻辑上首先是不合理的。但正常来说纯 IO 操作循环 1W 次应该不至于对 CPU 产生如此大的影响。
项目中使用 spring-boot-starter-data-redis 2.6.15,而 sprintboot 2.x.x默认使用的 redis 客户端为 lettuce(除非指定 spring.redis.client-type 或排除 lettuce 依赖))
-
进入业务代码发现是通过运营后台进行更新资源位配置来触发,异步将 [资源位ID所有城市渠道*模块] redis 缓存失效(暂时忽略这种代码逻辑的不合理),由于是使用线程池异步操作所以该接口响应很快。通过预发环境调用接口复现,借助 arthas 查看实际占用CPU 高的线程栈。
发现大量 ForkJoinPool 工作线程且多数运行在
managedBlock:[arthas@1405]thread -n 15 -i 2000 "ForkJoinPool.commonPool-worker-222" Id=1067 cpuUsage=4.28% deltaTime=225ms time=1710ms RUNNABLE at java.util.concurrent.ForkJoinPool.managedBlock(ForkJoinPool.java:3310) at java.util.concurrent.CompletableFuture.timedGet(CompletableFuture.java:1775) at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1915) at io.lettuce.core.protocol.AsyncCommand.await(AsyncCommand.java:83) at io.lettuce.core.internal.Futures.awaitOrCancel(Futures.java:244) at io.lettuce.core.LettuceFutures.awaitOrCancel(LettuceFutures.java:74) ... at java.util.stream.ForEachOpsForEachOpOfRef.accept(ForEachOps.java:184) at java.util.HashMapKeySpliterator.forEachRemaining(HashMap.java:1553) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.ForEachOpsForEachTask.compute(ForEachOps.java:291) at java.util.concurrent.CountedCompleter.exec(CountedCompleter.java:731) at java.util.concurrent.ForkJoinTask.originaldoExecmethodrenamedbyttl(ForkJoinTask.java:289) at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java) at java.util.concurrent.ForkJoinPoolWorkQueue.runTask(ForkJoinPool.java:1056) at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692) at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:157) "ForkJoinPool.commonPool-worker-95" Id=907 cpuUsage=3.26% deltaTime=171ms time=1767ms RUNNABLE at java.util.concurrent.ForkJoinPool.managedBlock(ForkJoinPool.java:3310) at java.util.concurrent.CompletableFuture.timedGet(CompletableFuture.java:1775) at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1915) at io.lettuce.core.protocol.AsyncCommand.await(AsyncCommand.java:83) ... "ForkJoinPool.commonPool-worker-135" Id=1310 cpuUsage=3.08% deltaTime=73ms time=730ms RUNNABLE at java.util.stream.ForEachOpsForEachOpOfRef.accept(ForEachOps.java:184) at java.util.HashMapKeySpliterator.forEachRemaining(HashMap.java:1553) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.ForEachOpsForEachTask.compute(ForEachOps.java:291) at java.util.concurrent.CountedCompleter.exec(CountedCompleter.java:731) at java.util.concurrent.ForkJoinTask.originaldoExecmethodrenamedbyttl(ForkJoinTask.java:289) at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java) - 大部分线程都来自线程池
commonPool,这里由于parallelStream()默认使用的线程池为静4. 大部分线程都来自线程池commonPool,这里由于parallelStream()**默认使用的线程池为静态变量java.util.concurrent.ForkJoinPool#common,所以在调用 lettuce api 时会进入managedBlock方法中的tryCompensate。managedBlock目的是在总线程数量不超过阈值的情况下,在当前任务不可释放(超时时间没到)的情况下,尽可能利用空闲线程或创建新线程执行任务,并且利用 do {} while 自旋及blocker.block()等待。public static void managedBlock(ManagedBlocker blocker) throws InterruptedException { ForkJoinPool p; ForkJoinWorkerThread wt; Thread t = Thread.currentThread(); // 判断是 forkjoinPool 的工作线程 if ((t instanceof ForkJoinWorkerThread) && (p = (wt = (ForkJoinWorkerThread)t).pool) != null) { WorkQueue w = wt.workQueue; // 任务是否可释放(这里实现是判断线程是否中断或是否到达超时时间) while (!blocker.isReleasable()) { // 尝试唤醒空闲线程或创建线程进行补偿执行队列中的任务 if (p.tryCompensate(w)) { try { // 等待 do {} while (!blocker.isReleasable() && !blocker.block()); } finally { U.getAndAddLong(p, CTL, AC_UNIT); } break; } } } else { do {} while (!blocker.isReleasable() && !blocker.block()); } }public boolean isReleasable() { if (thread == null) return true; if (Thread.interrupted()) { int i = interruptControl; interruptControl = -1; if (i > 0) return true; } // 判断是否达到超时 if (deadline != 0L && (nanos <= 0L || (nanos = deadline - System.nanoTime()) <= 0L)) { thread = null; return true; } return false; }tryCompensate****执行补偿逻辑:****需要补偿 :
- 调用者队列不为空,并且有空闲工作线程,这种情况会唤醒空闲线程(调用tryRelease方法)
- 池尚未停止,活跃线程数不足,这时会新建一个工作线程(调用createWorker方法)
不需要补偿 :
- 调用者已终止或池处于不稳定状态
- 总线程数大于并行度 && 活动线程数大于1 && 调用者任务队列为空
- 线程数量统计:
[arthas@1405]$ thread --all |grep 'ForkJoinPool.commonPool-worker' | wc -l 95另外在线程池创建的方法中
java.util.concurrent.ForkJoinPool#makeCommonPool其并行度为 *Runtime*.*getRuntime*().availableProcessors() - 1,那么正常在当前 4c8g 容器下,线程数量应该在 3 左右,这里怀疑是availableProcessors读取的是物理机的逻辑核心数。通过 arthas ognl 查看:

Google 后发现是 openJdk 旧版本问题,在 jdk 8u191 后才会正确读取容器可用核数(目前笔者线上使用的是 jdk1.8_181)
根因分析
本次问题的原因可以实际就是资源竞争激烈导致。
CPU 仅 4 核,执行大量 IO 任务的 ForkJoinPool 线程数量接近 100 个。虽然是 IO 密集型任务,但瞬时任务数量较多,且线程数量远大于核心数,此时线程疯抢 CPU 资源,IO 等待时间几乎没有。相当于对线程池进行压测。
解决方案
- 去掉 parallelStream 改为单线程 forEach
- 升级 openJdk 版本至 u18_202
- 分析代码业务场景,优化重构缓存同步逻辑。
- 另外可以考虑通过脚本在 CPU 使用率高时触发 jstack 方便排查定位问题
- 教育一下团队成员:laughing:
总结回顾
- 升级jdk后验证:
[arthas@1447]$ thread --all |grep 'ForkJoinPool.commonPool-worker' | wc -l
4
- ForkJoinPool 工作模型
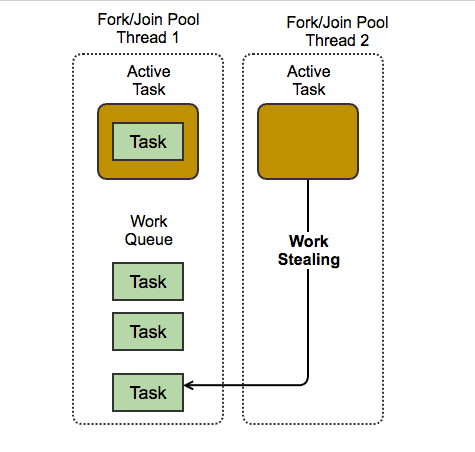
- 为什么说 ForkJoinPool 适合 CPU 密集型任务,不适合高 IO 任务呢?
原因是 ForkJoinPool 通过分治和窃取任务机制目的是把CPU核跑满,而一般 ForkJoinPool 默认情况下线程数量和CPU核数有关,跑 IO 任务容易产生阻塞,即出现工作线程数不够,这时如果任务中有依赖关系,甚至会出现死锁,从而影响整体效率。所以这个问题实际和线程数量及任务类型有关。
-
ForkJoinPool vs ThreadPoolExecutor
Fork/Join与ExecutorService的主要区别在于工作窃取算法(work-stealing algorithm)。Fork/Join是实现了工作窃取算法的一种特殊的ExecutorService。 不同于Executor 框架,当一个任务等待它通过fork操作创建的子任务完成时,执行该任务的线程(称为工作线程)会寻找其他还没被执行的任务,并且开始执行这些任务。也就是等在自己的子任务完成时,还可以执行其他任务。 通过这种方式,线程充分利用运行时间,因而改善了应用的整体性能。
-
适合使用 ForkJoinPool 的场景
1)The data-set is large & efficiently splittable.
2)The operations performed on individual data items should be reasonably independent of each other.
3)The operations should be expensive & CPU intensive.
参考
https://www.victorchu.info/posts/5c77d37/