
集群脑裂是什么?
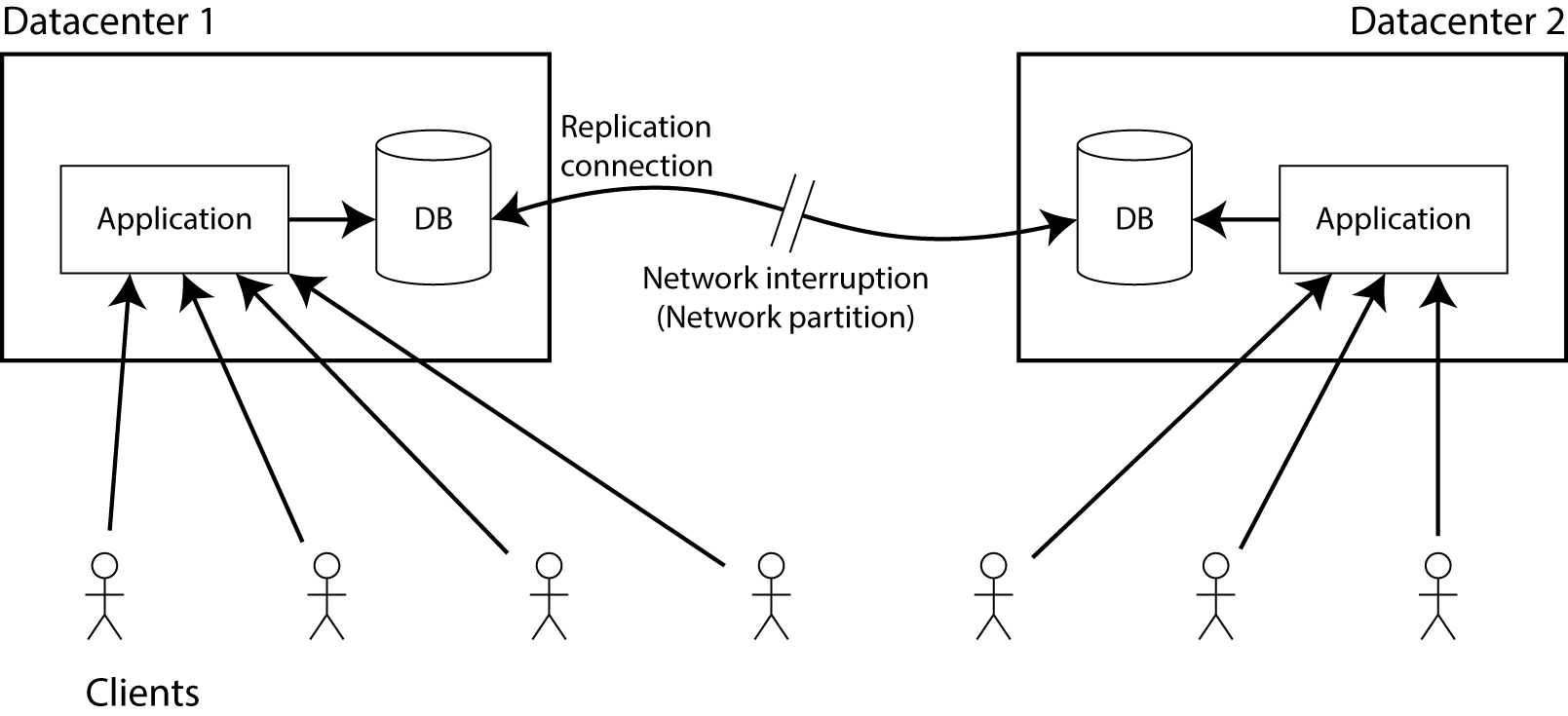
所谓集群中的“脑裂“(Split-Brain)问题(类似于人格分裂),指的是在分布式系统中,存在一个中心(Leader)节点,若 Leader 宕机或出现网络分区,分布式系统需要找到另一个节点顶替 Leader 角色。此时如果系统中存在两个(旧 Leader 假死或复活)或更多活跃 Leader 的情况,集群中的节点存在认知差异,被称为 “脑裂”。
危害是什么?
若集群存在多个主节点对外提供服务,那么可能会发生:
- 数据一致性被破坏,例如脑裂发生后,Client 连接的还是原 Leader1,集群恢复后,Leader1 可能会作为 Slave 存在,数据以新 Leader2 为准,那么 Client 在这段时间写入的数据就丢失了(或者考虑数据合并,这个合并的工作也非常困难问题,例如考虑共享资源操作的时间先后、是否幂等的因素)。
- 对外提供的服务出现异常。
原因有哪些?
网络问题、集群配置错误、节点故障、STW GC pause、软硬件问题等等。
怎么治?
通常的方案包括:
- Quorums(法定人数):通过设置法定人数,进而确定集群的容忍度,当集群中存活的节点少于法定人数,集群将不可用。
- 3 个节点的集群中,Quorums = 2 —— 集群可以容忍 (3 – 2 = 1) 个节点失败,这时候还能选举出 leader,集群仍然可用;
- 4 个节点的集群中,Quorums = 3 —— 集群同样可以容忍 1 个节点失败,如果2个节点失败,那整个集群就不可用了。
- Redundant communications(冗余通信):集群中采用多种通信方式,防止一种通信方式失效导致集群中的节点无法通信。
- Fencing(隔离,即共享资源):通过隔离的方式,将所有共享资源隔离起来,能对共享资源进行写操作(即加锁)的节点就是 leader 节点。
- 多副本备份:减少数据丢失。
- 节点监控和自愈:对节点进行实时监控,检测节点状态,及时发现分区问题,并自动或手动进行故障转移,避免数据不一致。
解决方案例子🌰
Redis 脑裂
Redis 集群架构常见的有 Redis Sentinel 和 Redis Cluster,内部都存在主从架构,而 Redis 的主从复制是异步的,所以Redis 无法完全避免脑裂的产生,因为其不保证主从的强一致,所以必然有产生脑裂的可能性。
为了降低脑裂带来的问题,Redis 提供配置用于防止主节点在异常情况下执行写入请求。
- min-slaves-to-write:主节点定时计算当前状态为连接的从节点数目,如果该数目小于”min-slaves-to-write”的值,则主节点拒绝执行写命令,(假设从库有 K 个,那么 min-slaves-to-write 可以设置为 K/2+1)。
- min-slaves-max-lag:如果从节点与主节点的最后交互时间,距离当前时间小于”min-slaves-max-lag”的值,则认为该从节点状态是连接的(用于计算上面的连接的从节点数量与 min-slaves-to-write 对比)。
虽然以上参数一定程度上可以降低脑裂的风险,但是也降低了 Redis 整体的可用性,是一种 trade off 方案。Redis 脑裂最本质的问题是主从集群内部没有共识算法来维护多个节点的强一致性,所以无法彻底解决。
Zookeeper 脑裂
从三个角度看 Zookeeper 如何解决脑裂问题:
- 选主
- Zookeeper 默认采用 Quorums 机制避免脑裂问题,只有获得超过半数节点的投票,才能选举出 Leader。这种方式可以确保要么选出唯一的 leader,要么选举失败。
- 写入
- ZooKeeper 的写也遵循 Quorums 机制,因此得不到大多数支持的写是无效的。
- 读取
- Zookeeper 保证了写入的强一致,即过半写。但由于 Zookeeper 允许客户端从从节点读取数据,可能存在从节点没有同步数据,所以不保证强一致读,只保证了读的顺序一致性,即最终一致,要保证读强一致需要调用 sync 方法。
- 如果客户端在读取过程中连接了不同的节点,正常来说是无法保证顺序一致的。而 Zookeeper 通过保证“单一视图”,保证不会连接到数据更老的从节点上。
ElasticSearch 脑裂
Elasticsearch 可以通过配置来应对脑裂问题
- discovery.zen.minimum_master_nodes :这个配置项就是最少包含 master 节点数,他指的是集群中至少有多少个 master 候选节点存在才能组成集群。官方推荐配置是 (N/2)+1,N 是 master 候选节点总数量,因此推荐 Elasticsearch 集群至少包含 3 个 master 节点。
- discovery.zen.ping_timeout:这个配置是存活检测时长,意即超过该配置项的时间内节点没有响应,则认为该节点出现故障脱离集群,默认值为 3 秒。适当增大该配置,可以降低误报的几率,减少 master 重新选举的可能。
总结
本文介绍了脑裂的定义及常见的解决方案,并列举了部分分布式中间件的方案,可以看到大部分都是采用 Quorums ****方案来应对脑裂问题。
参考