
过去进行线程池调优中会关注核心线程数、最大线程数等参数,总是忽略其中阻塞队列的选型。项目的线程池里随便塞一个
ArrayBlockingQueue或者 LinkedBlockingQueue再者一些场景使用 SynchronousQueue 等等。
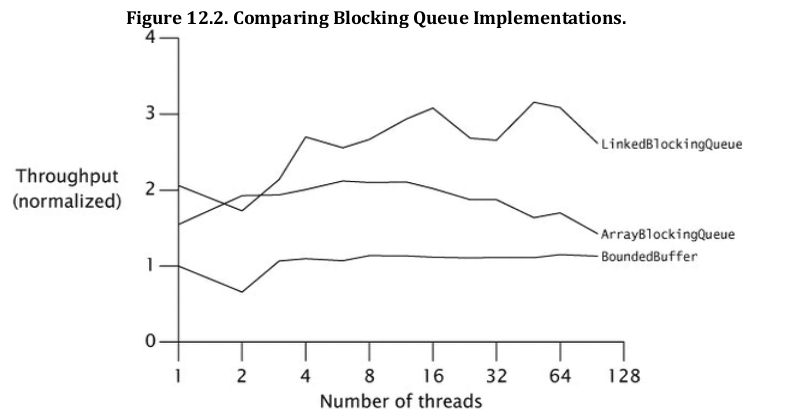
本篇主要总结ArrayBlockingQueue 和 LinkedBlockingQueue 之间的性能差异,以及 LinkedBlockingQueue 的实现细节。
阻塞队列是什么
阻塞队列首先是队列,即提供 FIFO 元素的能力。
阻塞表示需要支持阻塞式插入或取出元素(这里是支持不是一定要阻塞):
- 插入元素:当队列满了,线程阻塞等待,直到队列中的元素被取出,然后被唤醒继续往队列里面插入元素。
- 获取元素:队列为空,线程阻塞等待,直到队列有元素,被唤醒。
public interface BlockingQueue<E> extends Queue<E> {
// 插入失败则报错
boolean add(E e);
// 非阻塞插入,插入失败返回false
boolean offer(E e);
// 阻塞式插入,插入失败会阻塞
void put(E e) throws InterruptedException;
boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException;
// 阻塞式取
E take() throws InterruptedException;
// 阻塞一定时间后,取不到则返回null
E poll(long timeout, TimeUnit unit)
throws InterruptedException;
int remainingCapacity();
boolean remove(Object o);
public boolean contains(Object o);
int drainTo(Collection<? super E> c);
int drainTo(Collection<? super E> c, int maxElements);
阻塞队列实现原理
ArrayBlockingQueue
底层是通过数组实现的有界队列,初始化时必须传入队列的初始容量大小。并且内部维护一把锁用于控制读写。通过 Condition 实现读写线程等待队列。通过两个索引 takeIndex / putIndex 自增,指向下一个取/存的元素。
/** The queued items */
final Object[] items;
/** Main lock guarding all access */
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
/** items index for next take, poll, peek or remove */
int takeIndex;
/** items index for next put, offer, or add */
int putIndex;
LinkedBlockingQueue
它的特点是底层通过链表实现队列,可以支持有界或者无界(上限是 Integer.MAX_VALUE)队列,并且通过两把锁分别控制读写,因此操作粒度更细。同样通过 Condition 实现读写线程等待队列。
但是由于链表维护了节点指针,所以内存消耗上 ArrayBlockingQueue 更优一些。
/**
* Head of linked list.
* Invariant: head.item == null
*/
transient Node<E> head; // 用于出队
/**
* Tail of linked list.
* Invariant: last.next == null
*/
private transient Node<E> last; // 用于入队
/** Lock held by take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
Tomcat 线程池中默认使用 LinkedBlockingQueue ,Dubbo 配置线程池队列大小后,默认也是使用 LinkedBlockingQueue ,JUC 中 newFixedThreadPool() 也是使用LinkedBlockingQueue 。从这些也能看出它的性能必然优于 ArrayBlockingQueue 。
ps: Dubbo 默认线程池使用的阻塞队列是
SynchronousQueue,这个队列提供的是元素的传递而不存储任何元素。
当前没有其他线程正在执行 take 或 poll,则 offer 将失败。反之也会失败。即需要保证出和入是匹配的才能成功。
回到线程池场景下,由于线程池入队使用的是非阻塞的 offer 方法,对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则由于 offer 返回 fasle,则会立即新建一个线程来处理任务。
所以 SynchronousQueue 适合对响应要求比较高,或者线程池线程数量不固定的场景。
实现细节
可见性
对比ArrayBlockingQueue 只用一把锁,写写、写读线程通过同一个 Lock 保证可见性,实现上容易理解。而 LinkedBlockingQueue putLock 和 takeLock 两把锁,如何保证队列的变更的可见性?
// 没有 volatile 修饰
transient Node<E> head;
private transient Node<E> last;
// 首先 LinkedBlockingQueue 构造时头尾节点都是空节点
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
take() {
takeLock.lock()
dequeue() // from head
takeLock.unlock()
}
put() {
putLock.lock()
enqueue() // to last
putLock.unlock()
}
JDK 中 Doug Lea 对 LinkedBlockingQueue 注释写到:
/* Visibility between writers and readers is provided as follows:
*
* Whenever an element is enqueued, the putLock is acquired and
* count updated. A subsequent reader guarantees visibility to the
* enqueued Node by either acquiring the putLock (via fullyLock)
* or by acquiring the takeLock, and then reading n = count.get();
* this gives visibility to the first n items.
*/
即要么通过同一个 Lock 实现可见性,要么通过对 count (AtomicInteger 内部 volatile 修饰 value ,符合 Happens-Before 关系)进行读取来实现。
复习 Java 可见性实现:
Happens-Before 关系
(1)单线程规则: 在一个单独的线程中,按照程序代码的顺序,先执行的操作 happen-before 后执行的操作。也就是说,如果操作 x 和操作 y 是同一个线程内的两个操作,并且在代码里 x 先于 y 出现,那么有 hb(x, y)。
(2)锁操作规则(synchronized 和 Lock 接口等): 如果操作 A 是解锁,而操作 B 是对同一个锁的加锁,那么 hb(A, B)。
(3)volatile 变量规则: 对一个 volatile 变量的写操作 happen-before 后面对该变量的读操作。
(4)线程启动规则: Thread 对象的 start 方法 happen-before 此线程 run 方法中的每一个操作。
(5)线程 join 规则
(6)中断规则: 对线程 interrupt 方法的调用 happens-before 检测该线程的中断事件。
为什么 ArrayBlockingQueue 不采用两把锁呢?
ArrayBlockingQueue 采用*Object*[] items 存储数据,通过takeIndex 和 putIndex 分别作为取和存的索引,如果采用两把锁,需要考虑若同时操作一个节点造成的线程安全问题。
拓展
除了 JDK 自带的阻塞队列,还有其他高性能队列实现,例如 Disruptor 利用无锁(CAS)+ 缓存行填充 + 环形数组,提供了更强大的性能,笔者也在学习中,打算学成后另外总结一篇。
参考
https://gee.cs.oswego.edu/dl/cpj/jmm.html
https://stackoverflow.com/questions/35967792/when-to-prefer-linkedblockingqueue-over-arrayblockingqueue