
文章目录
背景
最近交接到一个项目,该项目主要提供少量 CRM 工具给线下运维人员使用,本想只是简单的维护。没想到在近期接入 Skywalking 后服务在某个燥热的午后频繁超时报警,业务反馈 APP 响应极慢。没想到竟是因为祖传代码…
(本文代码基于 tomcat 9.0.41)
解决过程
止损
止损正常操作是节点扩容或者进行变更回滚,查看监控发现流量侧并没有大的波动,但 heap 使用接近满载,FGC达到每2秒一次,另外前几天服务接入 Skywalking,考虑可能有关联,于是先尝试进行回滚,并且保留一个节点用于排查定位。
回滚后服务恢复访问,但观察发现 tenured generation used percentage 指标持续在增长并且基本保持在 85%+,但没有发生 OOM。
定位
初步判断是内存泄露问题,利用 jmap dump 内存快照排查具体泄露的对象,压缩文件拉到本地解压,利用 VisualVM 打开
jmap -dump:live,format=b,file=heap.hprof
tar -czvf heap.gz heap.hprof # 压缩一下,不然几个g下载还是比较慢的
tar -xzvf heap.gz # 解压
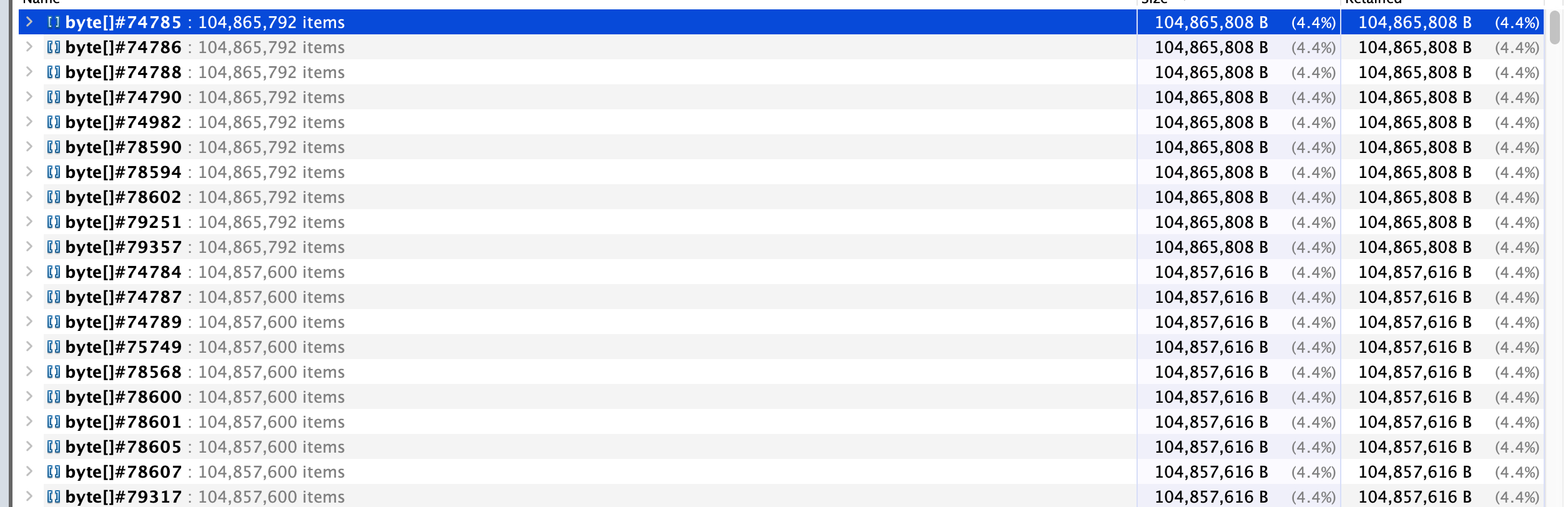
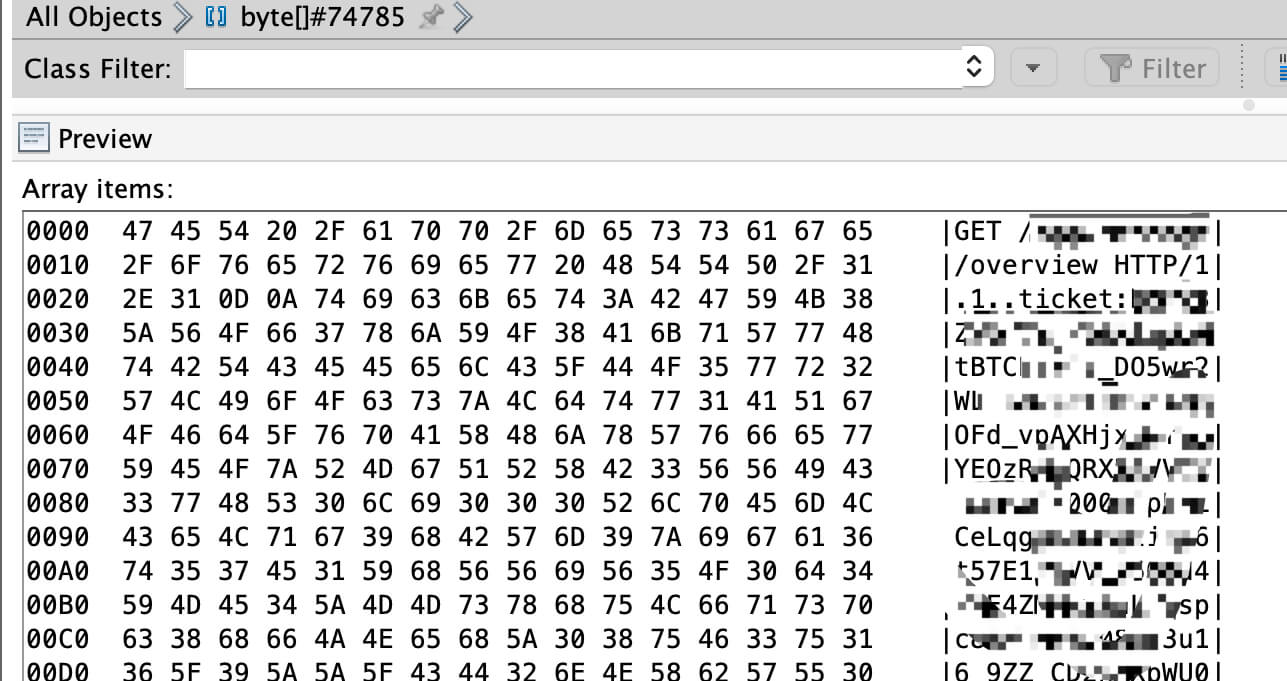
可以看到 20 个 byte[] 对象占用了 2G 的 heap,并且这个数组表示的内容是 http 请求相关。
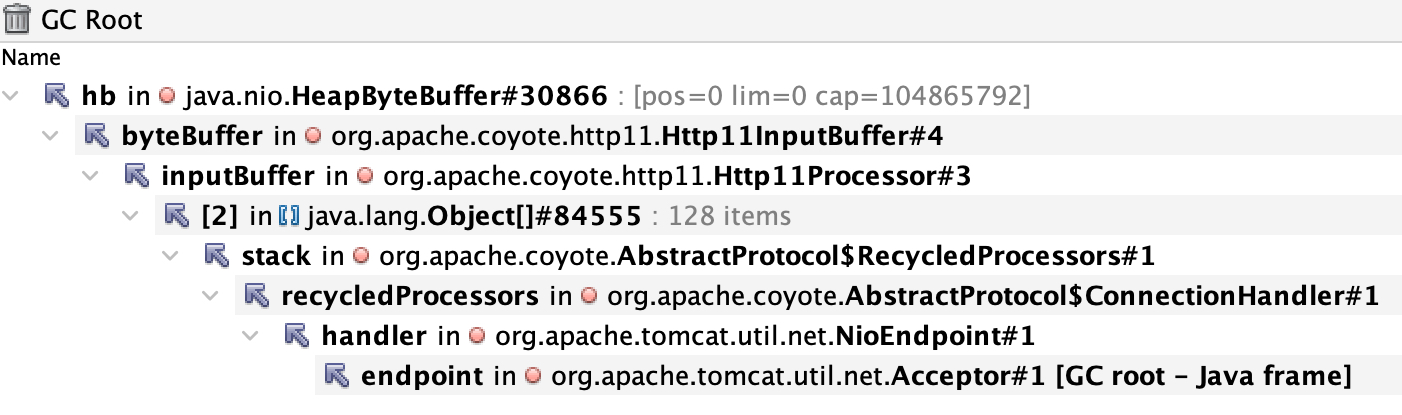
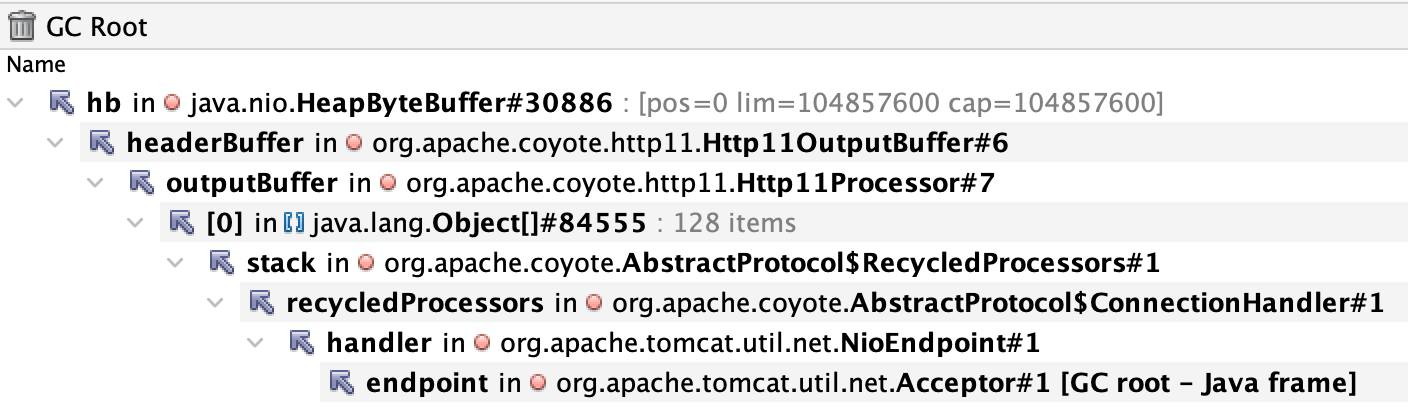
根据 GC ROOT 定位引用对象,这些 byte[] 分为两类,分别关联到了 tomcat 的对象 Http11InputBuffer、Http11OutputBuffer,并且每类对象数量正好是 10 个,并且每个对象的 retained size 正好 100M,那么总的大对象就占用了 2 * 10 * 100M = 2G,而该服务的配置为 Xms5g -Xmx5g -Xmn3g,老年代2G,只够存放 20 个这样的对象。
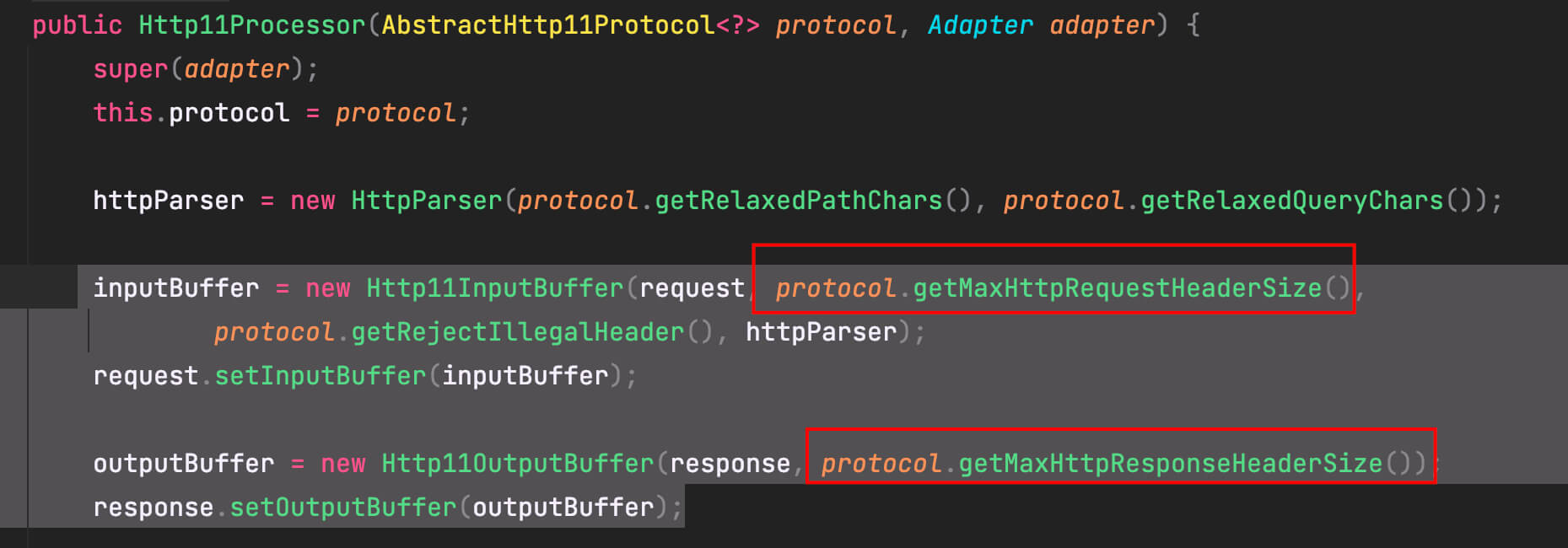
找到对应初始化的源码,虽然不知道这段代码的具体作用,但是根据变量名可以很明显看出来这是获取 http 请求/响应 header 的最大值。所以这里取的是 max-http-header-size,于是直接在代码中查找对应的配置,确实配置了 100M,自此内存泄露对象找到。
#这个参数非常重要,如果参数过小,会导致内容过长的邮件发送失败
server.max-http-header-size=104857600
解决
咨询之前交接过来的同事,确认这个配置的作用,对方表示是新建项目时从另外一个祖传代码 copy 过来的,并没有实际作用。于是删除该配置,采用 tomcat 默认值即可(8K)。
验证、发布
预防环境删除配置后请求服务,模拟并发请求内存占用正常。发布线上,接口恢复正常,一段时间内存在 GC 后保持在较低水位。
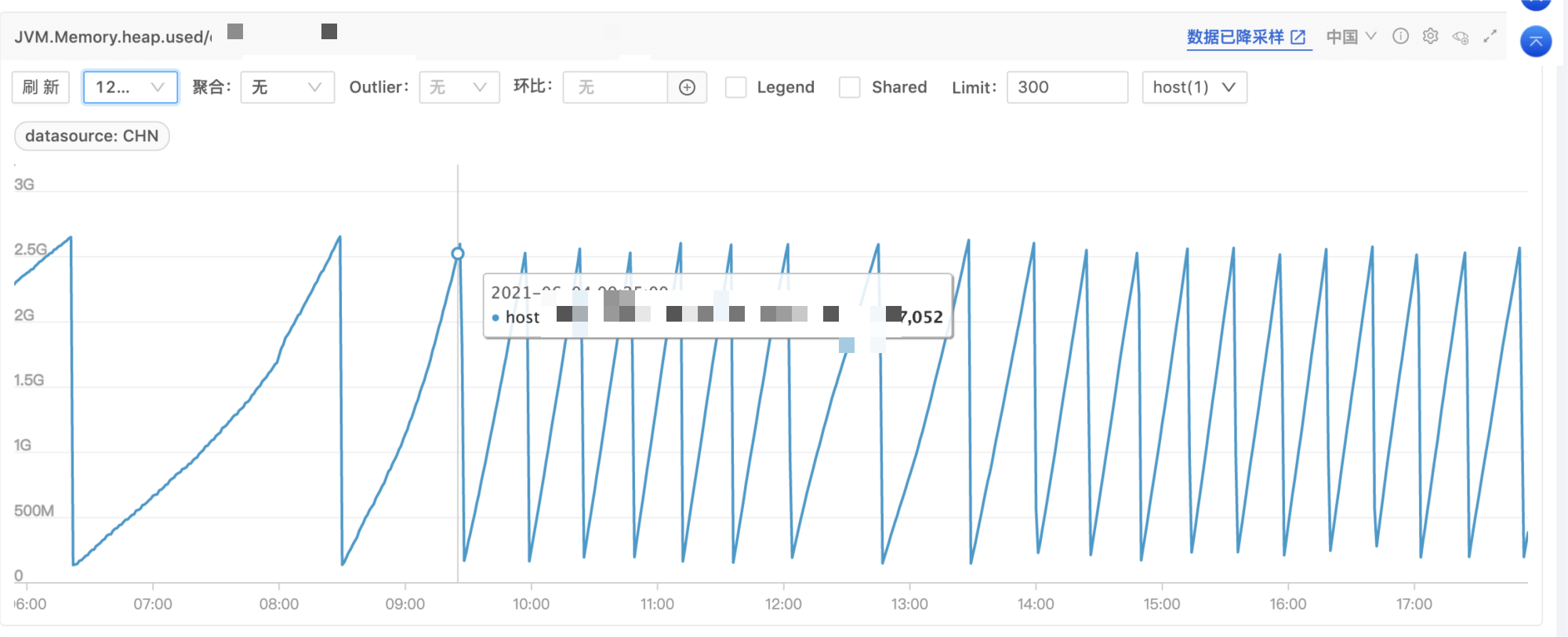
复盘
问题虽然解决,但目前为止仍然有个疑问,在代码交接后唯一的变更是增加了 Skywalking agent,为什么会直接导致服务假死呢?只要这个配置在线上应该早就暴露问题了,却一直到现在才出现故障?
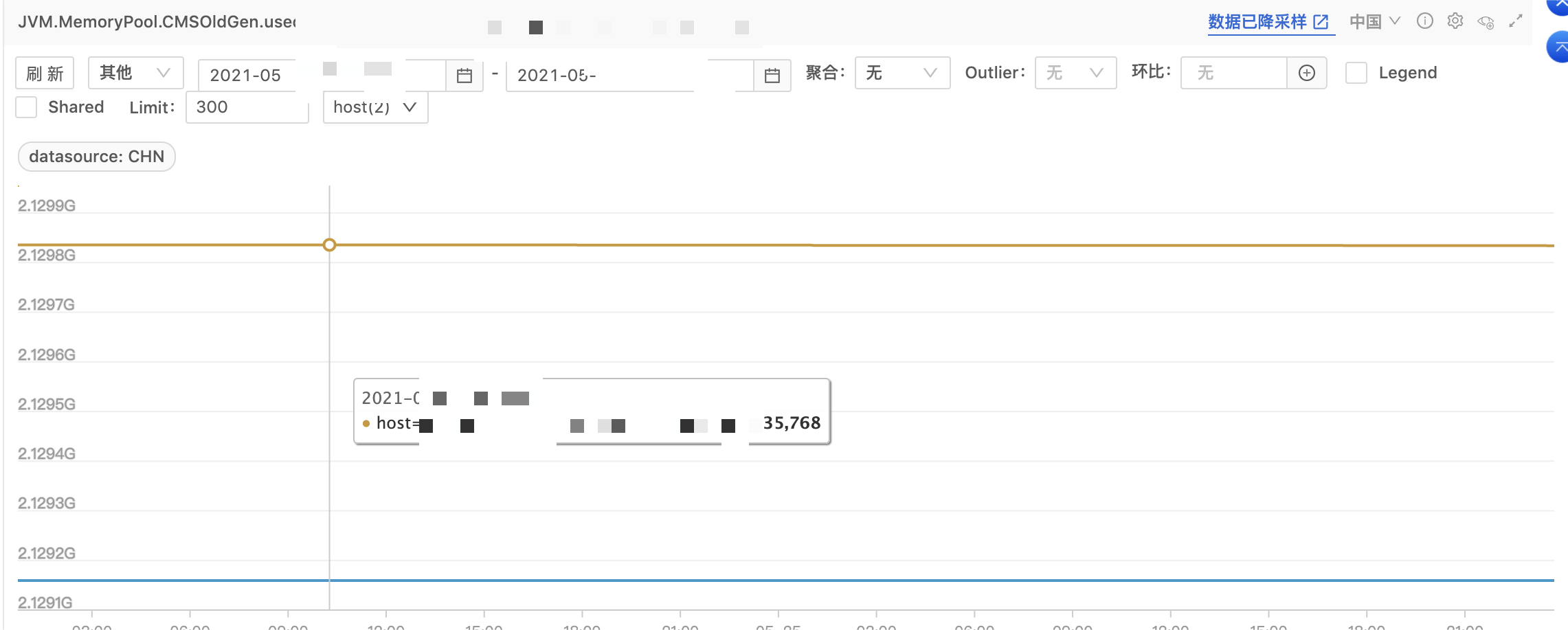
回看故障前的监控,可以看出老年代常年保持在 2G,而 CMS 也达到每小时几千次 Major GC,另外该项目配置了 CMSInitiatingOccupancyFraction=75, +UseCMSInitiatingOccupancyOnly,实际情况老年代几乎占用了 100%,所以 CMS background 一直在努力,却没有办法。因此其运行期间 STW 时间也相当客观(可惜该项目未打开 GC log,无法根据 log 分析)
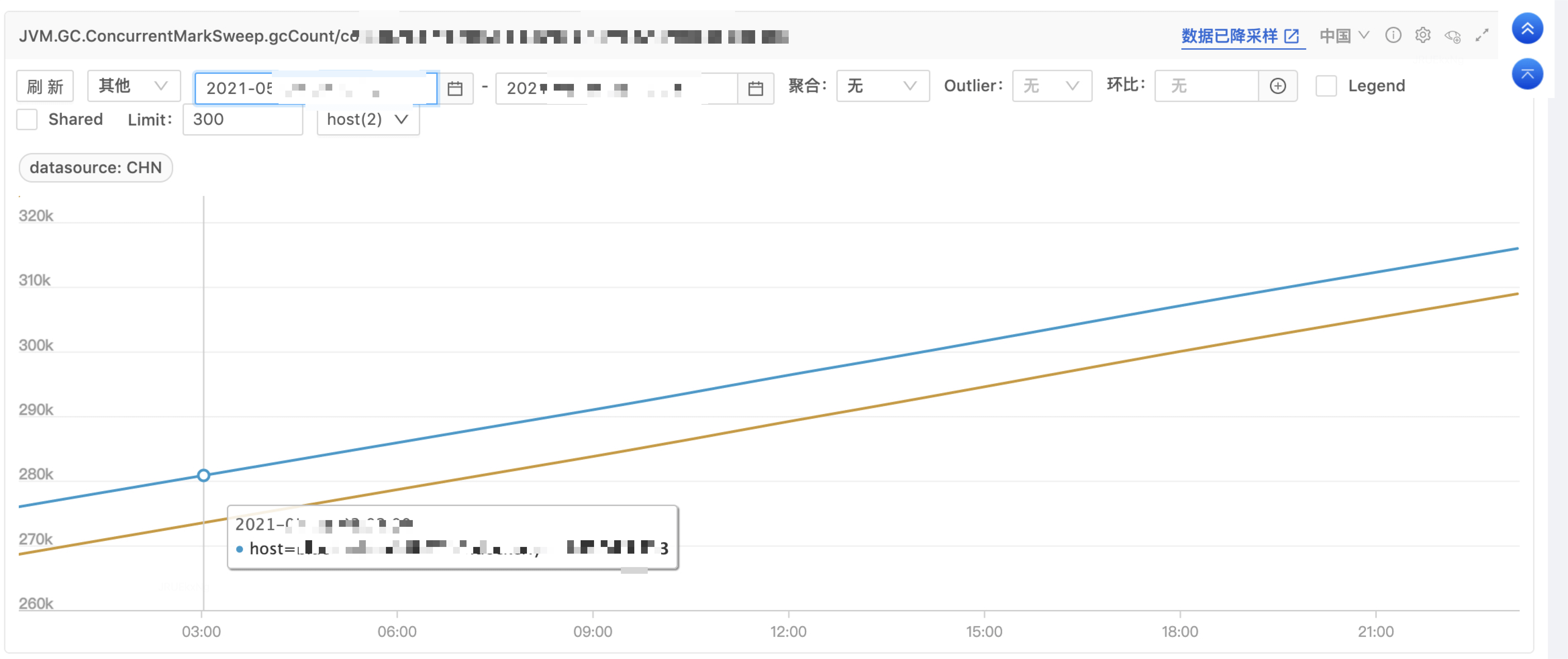
那么为什么 Http11InputBuffer、Http11OutputBuffer 无法被清理呢?正常理解这些 Buffer 虽然和请求相关,但是请求结束后连接断开,应该被清理才对?另外引用方 recycledProcessors 其命名说明大概率是存在复用的作用。
因此,根据 GC Root 追踪 tomcat 源码,在 Http1.1 协议初始化的位置创建了 ConnectionHandler,它的实例化方法中创建了 recycledProcessors ,底层是SynchronizedStack 保存了 ConnectionHandler 本身。
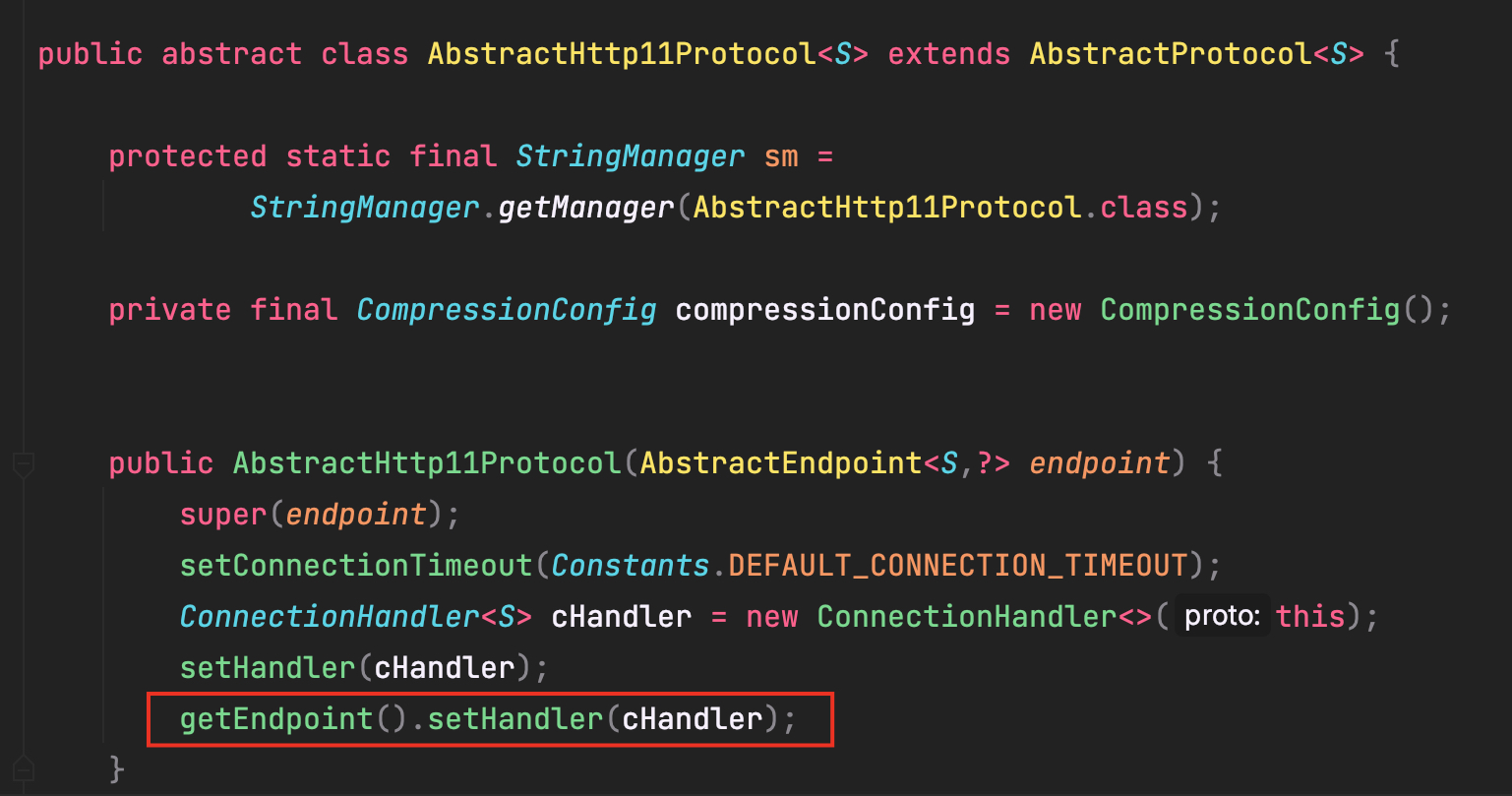

recycledProcessors 作用在 SocketProcessor 中体现,SocketProcessor 实现了 Runnable
作为线程池中的任务被提交到 tomcat 线程池,其封装了请求、响应的解析和 Servlet 分发等等。
下方代码是 SocketProcessor 通过 recycledProcessors 获取并回收 processor 的过程(这里就是 Http11Processor)
// NioEndpoint.SocketProcessor#doRun
// 获取 ConnectionHandler 并调用 process
getHandler().process(socketWrapper, SocketEvent.OPEN_READ);
// AbstractProtocol.ConnectionHandler#process
processor = recycledProcessors.pop();
...
release(processor);
|- recycledProcessors.push(processor);
综上得出由于 tomcat 为了性能考虑使用对象池,其被 NioEndpoint 关联,所以常驻老年代且无法被 GC。另外该服务还配置了另外一个参数MaxTenuringThreshold=2,因此新对象会在两次 YGC 后直接申请进入老年代,而老年代的空间总是不够的,这也是一个坑。
- 结论:
推测是由于当前项目接口主要是内部员工使用,对响应时间不敏感,而原来的响应时间预计正好没有大于超时时间。因此业务秉承“又不是不能用”,并没有主动反馈这个问题。而在接入 skywalking 后,增加了少许内存的消耗(官方测试大约在 5% 左右),增加了 foreground CMS 频率,STW 时间增加,导致服务不可用。
-
长期解决方案:
- 配置服务性能指标报警,以便能够及时发现非服务高峰期指标处于异常水位;
- 针对配置 CMS 的 JVM 进程手动配置;
XX:CMSInitiatingOccupancyFraction=n ,XX:+UseCMSInitiatingOccupancyOnly 指定触发CMS阈值,n 正常配置 80 左右且必须大于常驻老年代内存大小
Xloggc:gc_%t.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps 记录gc日志
MaxTenuringThreshold 一般6以上,太小容易提前晋升,太大影响新生代空间;
-
工程中的每个配置都需要清楚用途禁止随意配置;
- 有条件的可以在每次部署后触发自动化压测脚本。
拓展关于 CMS
回顾一下对象分配流程
- Use Thread Local Allocation Buffer (TLAB), if
tlab_top+size<=tlab_endThis is the fastest path. Allocation is just thetlab_toppointer increment. - If TLAB is almost full, create a new TLAB in Eden and retry in a fresh TLAB.
- If TLAB remaining space is not enough but is still to big to discard, try to allocate an object directly in Eden. Allocation in Eden is also a pointer increment (
eden_top+size<=eden_end) using atomic operation, since Eden is shared between all threads. - If allocation in Eden fails, a minor collection typically occurs.
- If there is not enough space in Eden even after Young GC, an attempt to allocate directly in Old generation is made.
CMS 触发时机
- foreground collector (被动触发,一般是遇到对象分配但空间不够,就会直接触发)
- 实际上是 Full GC,并不会走完整的 CMS GC 流程,省去了并行的阶段,例如Precleaning、AbortablePreclean,Resizing,所以整个过程都是 STW 的,对性能影响很大。
- background collector(CMS 后台线程扫描判断是否需要GC,默认间隔 2s,就是常见的 CMS GC)
- 初始标记(initial mark) 会 STW
- 标记GC Roots直接关联的对象以及年轻代指向老年代的对象
- 并发标记(Concurrent marking)
- 从GC Root向下追溯,标记所有可达的对象;但由于此时用户线程也在允许,会出现由于引用关系变动,活跃对象漏标的情况,可能有些对象,从新生代晋升到了老年代。可能有些对象,直接分配到了老年代(大对象)。可能老年代或者新生代的对象引用发生了变化。针对老年代在此并行阶段的变化,使用 card table,对于老年代产生变化的页标记为dirty,后续阶段对于老年代只需要扫描这部分增量变化
- 对于漏标存活对象,采用增量更新+写屏障解决
- 从GC Root向下追溯,标记所有可达的对象;但由于此时用户线程也在允许,会出现由于引用关系变动,活跃对象漏标的情况,可能有些对象,从新生代晋升到了老年代。可能有些对象,直接分配到了老年代(大对象)。可能老年代或者新生代的对象引用发生了变化。针对老年代在此并行阶段的变化,使用 card table,对于老年代产生变化的页标记为dirty,后续阶段对于老年代只需要扫描这部分增量变化
- 并发预处理(Concurrent precleaning)
- 主要工作是标记,以减少下一阶段重新标记的处理时间,由于上一步由于用户线程并行,对象可能有变化,这一步工作如下:1. 对于新生代引用老年代的变化,就需要在该重新扫描新生代,一般会伴随一次minor gc,减少新生代需要扫描的对象数量2. 对于老年代自身的变化,那么就扫描 card table,即可对存活的老年代对象做标记
- 重新标记(remark) 会 STW
- 重新标记,为了修正并发标记期间因用户程序继续运作产生变动的对象和新创建的对象
- 并发清理(Concurrent sweeping)
- 产生浮动垃圾,因为和用户线程并行,用户线程可能不断产生垃圾
- 并发重置(Concurrent reset)
- 初始标记(initial mark) 会 STW
分区大小参数基本策略
各分区的大小对GC的性能影响很大。如何将各分区调整到合适的大小,分析活跃数据的大小是很好的切入点。
活跃数据的大小是指,应用程序稳定运行时长期存活对象在堆中占用的空间大小,也就是Full GC后堆中老年代占用空间的大小。可以通过GC日志中Full GC之后老年代数据大小得出,比较准确的方法是在程序稳定后,多次获取GC数据,通过取平均值的方式计算活跃数据的大小。活跃数据和各分区之间的比例关系如下(见参考文献1):
| 空间 | 倍数 |
|---|---|
| 总大小 | 3-4 倍活跃数据的大小 |
| 新生代 | 1-1.5 活跃数据的大小 |
| 老年代 | 2-3 倍活跃数据的大小 |
| 永久代 | 1.2-1.5 倍Full GC后的永久代空间占用 |
例如,根据GC日志获得老年代的活跃数据大小为300M,那么各分区大小可以设为:
总堆:1200MB = 300MB × 4* 新生代:450MB = 300MB × 1.5* 老年代: 750MB = 1200MB – 450MB*
这部分设置仅仅是堆大小的初始值,后面的优化中,可能会调整这些值,具体情况取决于应用程序的特性和需求。
MaxTenuringThreshold 动态调整机制
动态年龄计算:Hotspot 遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了survivor区的一半时,取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值。在本案例中,调优前:Survivor区 = 64M,desired survivor = 32M,此时Survivor区中age<=2的对象累计大小为41M,41M大于32M,所以晋升年龄阈值被设置为2,下次Minor GC时将年龄超过2的对象被晋升到老年代。
JVM引入动态年龄计算,主要基于如下两点考虑:
- 如果固定按照 MaxTenuringThreshold 设定的阈值作为晋升条件:
- MaxTenuringThreshold设置的过大,原本应该晋升的对象一直停留在Survivor区,直到Survivor区溢出,一旦溢出发生,Eden+Svuvivor中对象将不再依据年龄全部提升到老年代,这样对象老化的机制就失效了。
- MaxTenuringThreshold设置的过小,“过早晋升”即对象不能在新生代充分被回收,大量短期对象被晋升到老年代,老年代空间迅速增长,引起频繁的Major GC。分代回收失去了意义,严重影响GC性能。
- 相同应用在不同时间的表现不同:特殊任务的执行或者流量成分的变化,都会导致对象的生命周期分布发生波动,那么固定的阈值设定,因为无法动态适应变化,会造成和上面相同的问题。
总结来说,为了更好的适应不同程序的内存情况,虚拟机并不总是要求对象年龄必须达到Maxtenuringthreshhold 再晋级老年代。
以下是计算 MaxTenuringThreshold 源码
int ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
//TargetSurvivorRatio默认为50
//desired_survivor_size = survivor的空间*50%
size_t desired_survivor_size = (size_t)((((double) survivor_capacity)*TargetSurvivorRatio)/100);
size_t total = 0;
int age = 1;
assert(sizes[0] == 0, "no objects with age zero should be recorded");
while (age < table_size) {
// 循环遍历所有年龄代的对象累加得到一个大小
total += sizes[age];
// 如果该大小大于desired_survivor_size,即survivor的空间*50%,那么退出循环
if (total > desired_survivor_size) break;
age++;
}
// 如果算出来的age大于MaxTenuringThreshold则使用MaxTenuringThreshold,否则使用计算出来的age
int result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
if (PrintTenuringDistribution || UsePerfData) {
if (PrintTenuringDistribution) {
gclog_or_tty->cr();
// 这里就是线上出现的那个日志所在的地方
gclog_or_tty->print_cr("Desired survivor size %ld bytes, new threshold %d (max %d)",
desired_survivor_size*oopSize, result, MaxTenuringThreshold);
}
//....
}
// 返回计算的年龄
return result;
}
CMS 特有的两个问题(主要由于浮动垃圾导致内存碎片)
- promotion failed
- 进行Minor GC时,Survivor Space放不下,对象只能放入老年代,而此时老年代也放不下造成的,多数是由于老年带有足够的空闲空间,但是由于碎片较多,这时如果新生代要转移到老年带的对象比较大,所以,必须尽可能提早触发老年代的CMS回收来避免这个问题。直觉上乍一看这种情况可能会经常发生,但其实因为有 concurrentMarkSweepThread 和担保机制的存在,发生的条件是很苛刻的,除非是短时间将 Old 区的剩余空间迅速填满
- 解决办法:-XX:UseCMSCompactAtFullCollection -XX:CMSFullGCBeforeCompaction=5 即进行标记整理清除碎片或者调大新生代 Survivor 空间。
- concurrent mode failure
- CMS垃圾收集器特有的错误,CMS的垃圾清理和引用线程是并行进行的,如果在并行清理的过程中老年代的空间不足以容纳应用产生的垃圾(也就是老年代正在清理,从年轻代晋升了新的对象,或者直接分配大对象年轻代放不下导致直接在老年代生成,这时候老年代也放不下),则会抛出“concurrent mode failure”。
- 影响:老年代的垃圾收集器从 CMS 退化为 Serial Old,所有应用线程被暂停,停顿时间变长。
CMS 空间分配担保机制
- 在发生minorGC之前,虚拟机必须检查老年代中最大可用的连续空间是否大于新生代所有对象的总空间,
- 如果条件成立,则认为这次minorGC是安全的;
- 如果条件不成立,虚拟机会查看 handlePromotionFailure 参数是否允许担保失败,如果允许担保失败,那么会继续检查老年代中最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试一次minorGC
- 如果小于或者不允许担保失败,那么就会发生FullGC
参考:
https://tech.meituan.com/2020/11/12/java-9-cms-gc.html
https://tech.meituan.com/2017/12/29/jvm-optimize.html
https://developer.jdcloud.com/article/2853
https://stackoverflow.com/questions/24618467/size-of-huge-objects-directly-allocated-to-old-generation